GPT 本質上就是 Transformer 的 decoder
GPT-1
paper: Improving Language Understanding by Generative Pre-Training
用 semi-supervised,後來被歸為 self-supervised
Unsupervised pre-training
$L_1(U)=\sum_i logP(u_i|u_{i-k},…,u_{i-1};\theta)$
$U= \{ u_1,…,u_n \}$
$U$ 是一系列未標記的文本 token
$k$ 是窗口大小
模型大致架構
$h_0=UW_e+W_p$
$h_1=transformer \_ block(h_{i-1})\forall i \in[1,n]$
$P(u)=softmax(h_nW^T_e)$
$U=\{u_{-k},…,u_{-1}\}$
Supervised fine-tuning
$P(y|x^1,…,x^m)=softmax(h^m_lW_y)$
$L2(C)=\sum_{(x,y)}log P(y|x^1,…,x^m)$
$L_3(C)=L_2(C)+\lambda*L_1(C)$
$C$ 是 labeled 的資料集,微調基本上就是在後面加上線性層
作者最大化 likelihood 的時候是用 $L_3$ 而非單純的 $L_2$
微調應用範例
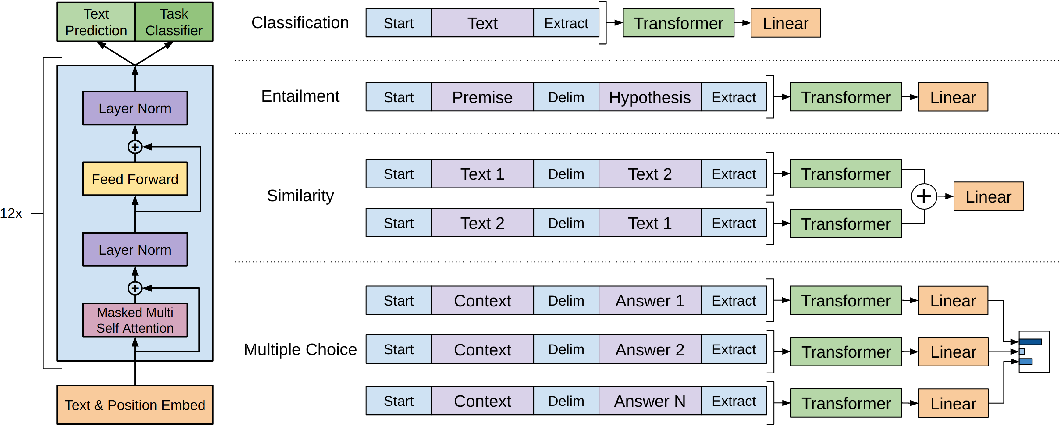
資料集
用 BooksCorpus 訓練出來的
有超過 7000 本未出版的書
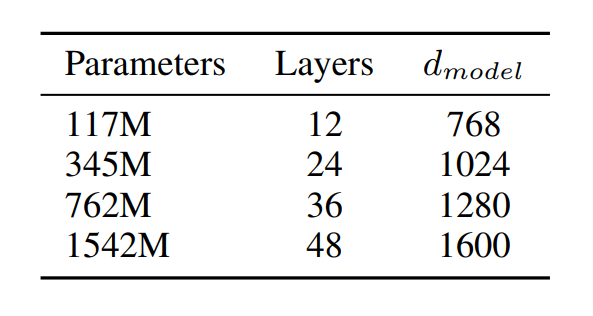
模型結構
- 12 層 transformer 的 decoder
- 768 維 word embedding
- 12 個 attention heads
和 BERT BASE 比較
BERT 論文比較晚出,但 BASE 的模型架構和 GPT 有相似之處,
BASE 是 12 層的 decoder,word embedding 和 attention head 的維度或數量和 GPT-1 相同
GPT-2
paper: Language Models are Unsupervised Multitask Learner
GPT-2 除了用更大的的模型和更大的資料集,把重點放在 zero-shot 上,雖然在 GPT-1 的論文就有提過 zero-shot
資料集
這次做了一個叫做 WebText 的資料集,有百萬級別的網頁
Common Crawl
大型爬蟲專案,有大量網頁資料,但充斥了垃圾訊息
WebText
WebText 的資料來源是 reddit 上的外部連結,只要有至少三個 karma,就會被採納,由此取得品質較好的網頁資料。透過這種方法,取得了 4500 萬個連結。並用Dragnet (Peters & Lecocq, 2013) and Newspaper content extractors 把文字訊息從 HTML 中抓出來
架構
和原本差不多,變成有 1.5B 參數的 Transformer decoder
zero-shot
不需要下游任務的標記資料
改把任務輸入進模型
目前問題
- 現在的模型泛化能力不太好
- Multitask learning
在 NLP 上不太常用,NLP 現在主流還是在預訓練模型上做微調以應對下游任務
- 對每個下游任務都得重新訓練模型
- 得蒐集 labeled 資料
結果
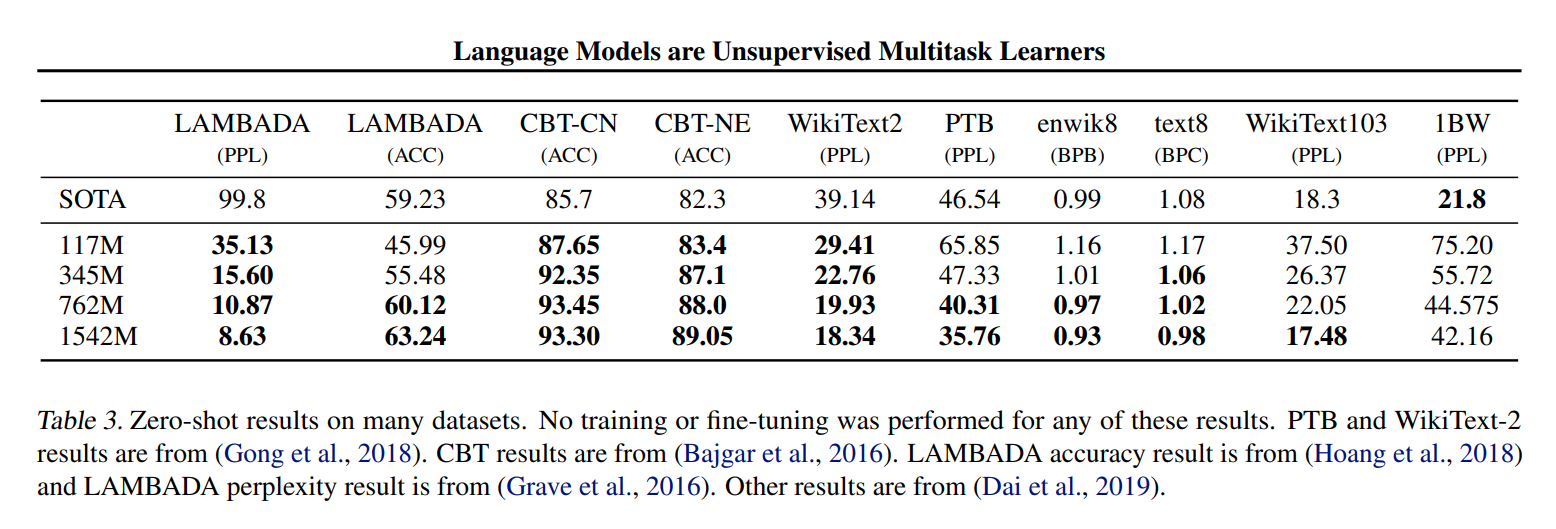

GPT-3
paper: Language Models are Few-Shot Learners
摘要
- 有 175B 的參數,由於模型極大,要在子任務微調會成本很大,所以不做任何梯度更新
- 在很多 NLP 任務有傑出的成果
- 可以生出人類難以區分的新聞文章
目前有的問題
- 要在子任務微調,需要資料集
- 微調後在有些子任務上表現好不代表你預訓練模型一定泛化能力高
- 人類不需要大量 labeled 資料去完成小任務
評估方式
- 分為三種,few / one / zero-shot learning
架構
基本上 GPT-3 和 GPT-2 架構一樣
相同
- modified initialization
- pre-normalization
- reversible tokenization described therein
不同
- 把 Sparse Transformer 的一些修改拿過來用
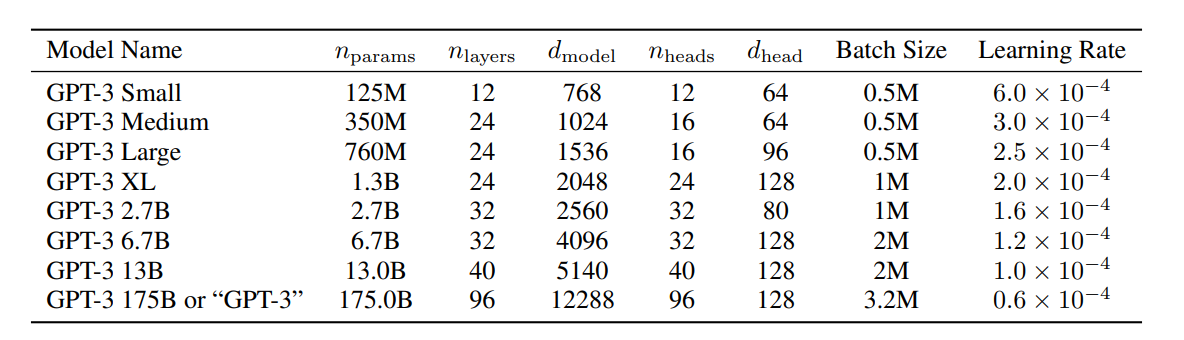
GPT-3 Small 是 GPT-1 的大小 GPT-3 Medium 是 BERT Large 的大小 GPT-3 XL 和 GPT-2 相近,比較淺也比較寬
Batch Size 大小
模型小的時候需要小一點,透過這種額外的 noise 來避免 overfitting(不確定是不是猜想)
資料集
Common Crawl
架構比 GPT-2 大很多,所以回頭考慮這個資料集
三步驟
- 先過濾,透過 reddit 那個高品質的資料集,來訓練一個模型分類高品質和低品質的網頁。
- 透過 LSH 演算法把相似的文本過濾掉
- 把一些已知高品質的資料集也加進來
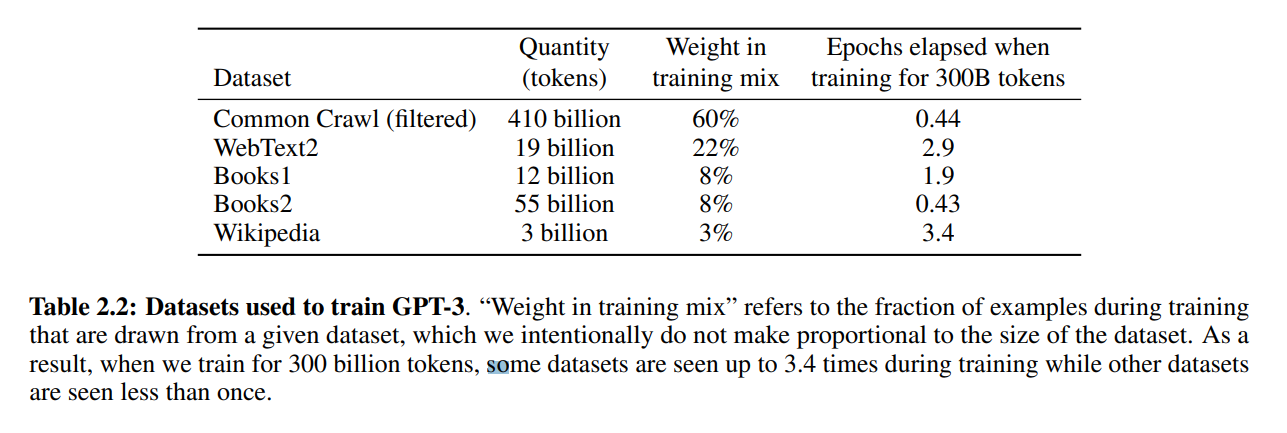
這是一個 Batch 裡有 60% 來自 Common Crawl(filtered) 的意思 Wikipedia 雖然總量比較少,但也有 3% 的採樣率
結果
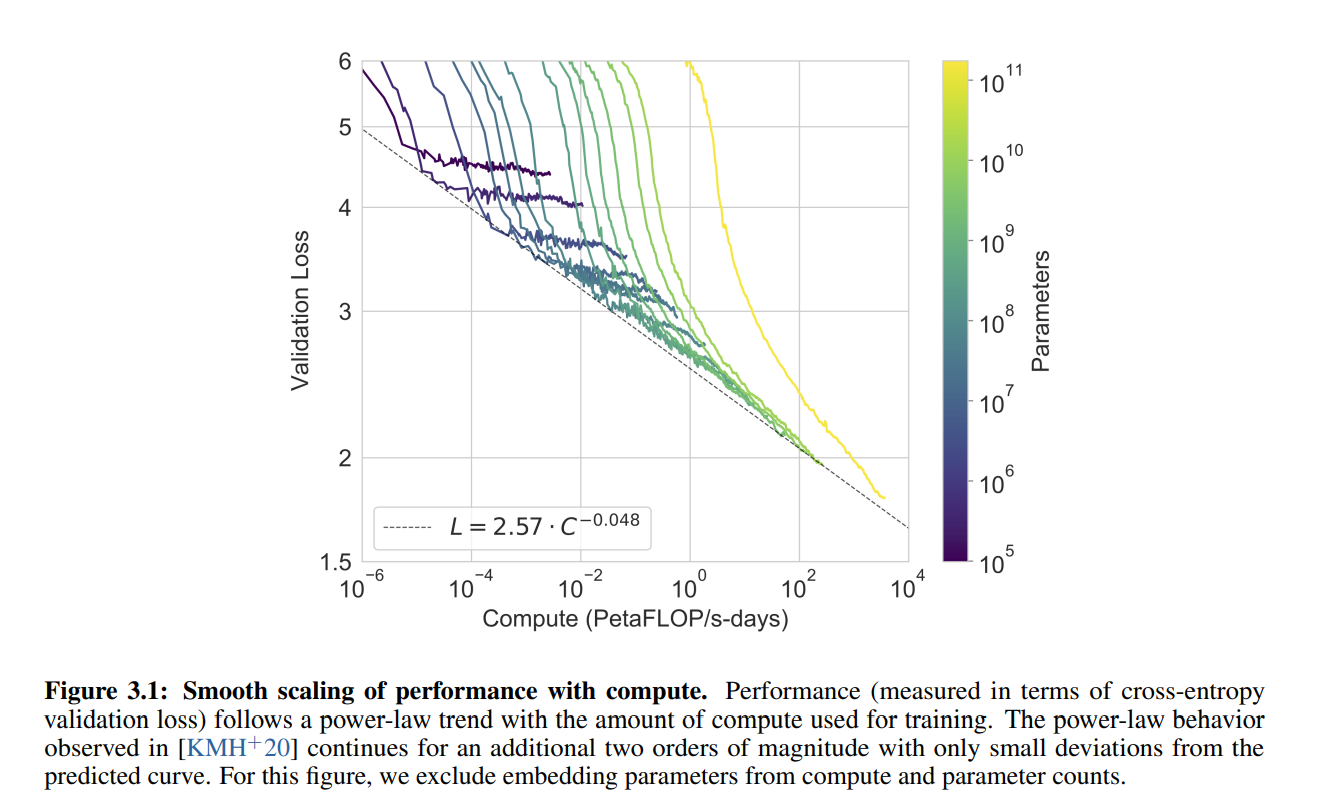
計算量指數增長,loss 卻是線性的往下降
paper 裡有很多任務的實驗結果,這邊就不附上了
Limitations
在文本生成上還是比較弱,生很長的東西,可能會重複自己說過的話、失去連貫性、自相矛盾等等
在有些雙向性的任務上可能表現更差
影響
- 可能被用來散布不實消息、垃圾郵件等等
- 偏見
結論
在很多 NLP 任務可以做到接近 SOTA 微調模型的成果