paper: Masked Autoencoders Are Scalable Vision Learners
Abstract
這篇論文顯示出 MAE 是 CV 中的 scalable self-supervised learners。
MAE 的方法很簡單
- 隨機蓋住輸入影像的一些 patch
- 重建 missing pixels
具備兩個核心設計
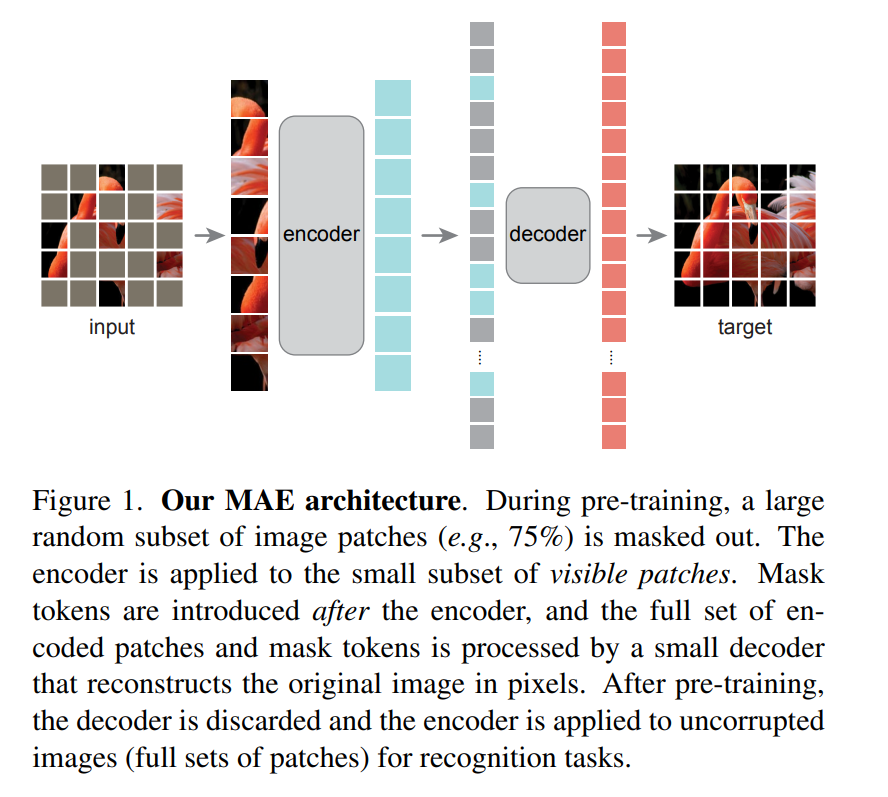
- 非對稱的 encoder-decoder 架構,encoder 只作用於可見的 patch 子集合(沒有 mask tokens),lightweight decoder 則根據 latent representation 和 make tokens 來重建圖片。
- 當遮住高比例(比如 75%)的影像時,會得到一個 nontrivial 和 meaningful 的 self-supervisory task
結合這兩點設計,可以有效地訓練大模型。 以 ViT-Huge 用 ImageNet-1K 訓練(訓練集一百多萬張照片)可達到 87.8% 的準確度。
Introduction


在 CV 中,常需要大量 labeled images。 NLP 中,自監督預訓練處理了需要大量標註資料的問題。 masked autoencoders 是一種更 general 的 denoising autoencoders 的形式。 BERT 非常成功,autoencoding methods 在 CV 的研究卻落後 NLP,作者思考是什麼讓 masked autoencoding 在 CV 和 NLP 產生不同。 有以下觀點
- 直到前陣子,CV 中的 CNN 是主流,但卷積層不好引入 mask tokens 或 positional embedding 這些 indicator。但這些可以透過 ViT 來解決,不應成為問題。
- 語言和視覺的 Information density 不同,語言是 highly semantic 和 information-dense,使填字本身不是很簡單的事情,但影像含有大量冗餘的訊息,缺失的部分比較好從相鄰的 patch 重建,比如直接插值,所以作者用一種簡單的策略,隨機 mask 很大一部分的 patch,創造一個具有挑戰性的自監督任務,強迫模型關注 global 的資訊。
- 關於 decoder,CV 還原 pixel,pixel 屬於 lower semantic level,NLP 還原 word,word 的 semantic information 較高。作者發現,雖然在 BERT 中,可以用簡單的 decoder 還原(一個 MLP),但 CV 中 decoder 的設計就很重要。
基於以上觀點,作者提出 MAE,隨機遮住大量的 patch,並在 pixel space 重建失去的 patch。而且是非對稱 encoder-decoder 架構,encoder 只會看到可見的 patch,但 docoder 除了 latent representation,還會看到 mask tokens。這種設計在非常高的掩蓋率(比如 75%)下不但可以提高準確度,還可以讓 encoder 只處理較少比例(比如 25%)的 patch,將訓練時間減少 3 倍或更多,使 MAE 可以輕鬆擴展成更大的模型。
在這樣的架構下,用 MAE 的 pre-training,可以訓練非常吃 data 的模型,比如 ViT-Large/-Huge,而只使用 ImageNet-1K。
用 ImageNet-1K 在 vanilla ViT-Huge 上 fine-tune 可達到 87.8% 準確度,比以往只使用 ImageNet-1K 的結果都高。
在 obejct detection、instance segmentation、semantic segmentation 上做 transfer learning 都達到不錯的效果,可以打敗用監督式預訓練模型的對手。
相關工作
- Autoencoding
- MAE 是一種 denoising autoencoding 的形式,但和 DAE 還是差別很大。
- Masked image encoding
- iGPT、ViT、BEiT
Approach
-
Masking
- 和 ViT 一樣,把圖片切成多個 patch,對於 patch 均勻隨機地採樣保留,剩下地遮住
-
MAE encoder
- ViT
- 也有 positional embedding
-
MAE decoder
- Transformer block
- 輸入
- encoded visible patches
- mask tokens
- shared, learned vector
- 都會加入 positional embedding
- 用相較 encoder 輕量的解碼器,所有的 patch 由這個輕量的 decoder 處理,減少預訓練時間
-
Reconstruction target
- decoder 的最後一層是 linear projection,之後再 reshape 成你要的 patch
- loss function
- mean squared error(MSE)
- 只算 masked patched 的 MSE,像 BERT
-
Simple implementation
- 先取得一系列 token(patch 做 linear projection + positional embedding)
- randomly shuffle,根據比例移除尾端一部份
- encoding 後,尾端接上 mask tokens,並且 unshuffle
- 加上 positional embedding 後,給 decoder
ImageNet Experiments
在 ImageNet-1K 上做自監督的預訓練,然後做
- end-to-end fine-tuning
- 所有參數都可改
- linear probing
- 只改最後一層線性層
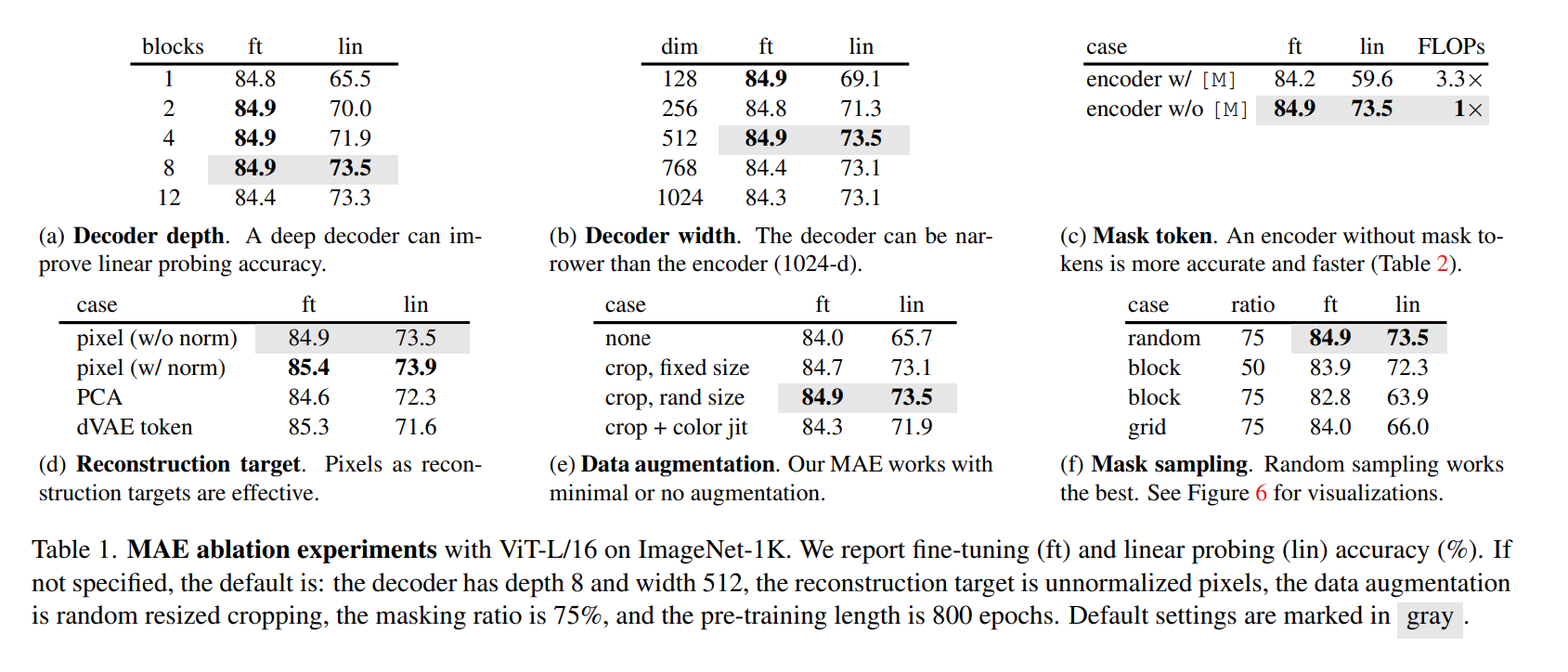
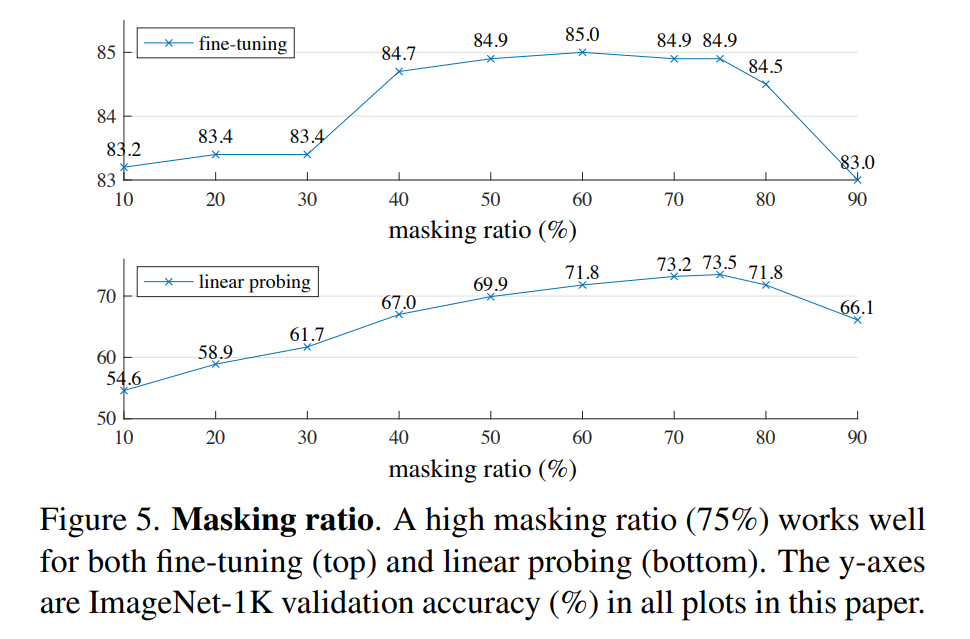
optimal masking ratio 意外地高,相比 BERT 只有 15%

討論和結論
在 CV 實用的預訓練做法主流是監督式的,CV 中自監督的做法可能正跟著 NLP 的軌跡走。
要仔細處理圖像和語言的區別,作者去除圖片中很可能不構成 semantic segment 的部分,而不是移除某個 object。