paper: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Abstract
在 CV 領域 transformer 表現有限,目前 attention 常常是和卷積神經網路一起用,或是用來把一些卷積層換成 self-attention,但整體架構不變。這篇論文想展現一個純 Transformer 可以直接在影像分類上表現很好。如果用大量資料作預訓練,再遷移到中小型的資料集,可以和 SOTA 的 CNN 表現得一樣好,還需要較少的訓練資源作訓練。
Introduction
self-attention-based 架構,特別是 Transformer,已經是 NLP 的重要選擇。主流的作法是在大型文字資料集上作訓練,再針對小型任務資料集作 fine-tune。由於 Transformer 的計算效率高,還有可擴展性,可以 train 一些很大的 model,隨著 model 和資料集增大,目前還沒看出飽和的現象。
然而在 CV,CNN 還是主流,一些工作嘗試用 self-attention 結合 CNN-like 的架構,比如把 feature map 當 transformer 的輸入,因為原始 pixel 太多,或甚至把卷積層全換成 self-attention,雖然後者理論上效率很高(原論文中有另外 cite 兩篇作法),但因為他們做法特殊,在現代硬體上很難加速,所以無法很有效地擴展。在 large-scale 的影像識別上, ResNet-like 的架構還是 SOTA。
該實驗直接把一個標準的 Transformer 作用於圖片上,只作最少的修改。把影像分成多個 patch,並把它們變成一系列的 linear embedding,當作 NLP 中的 tokens(words) 來處理。
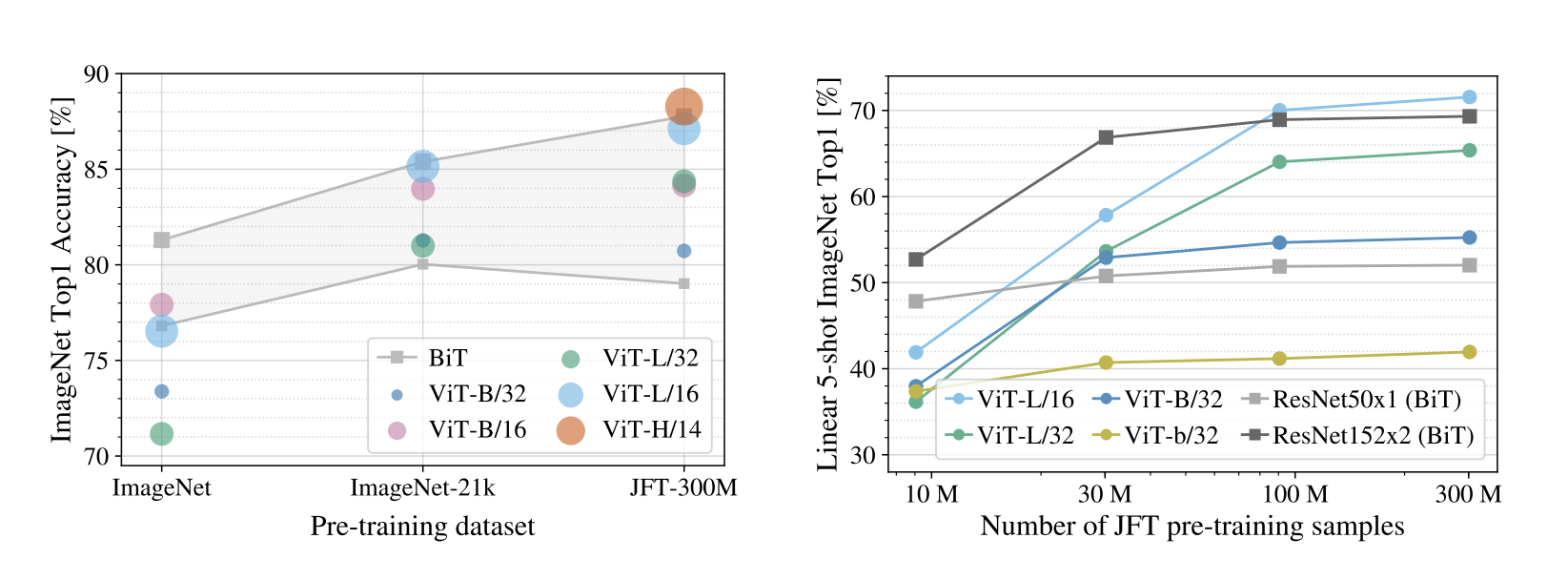
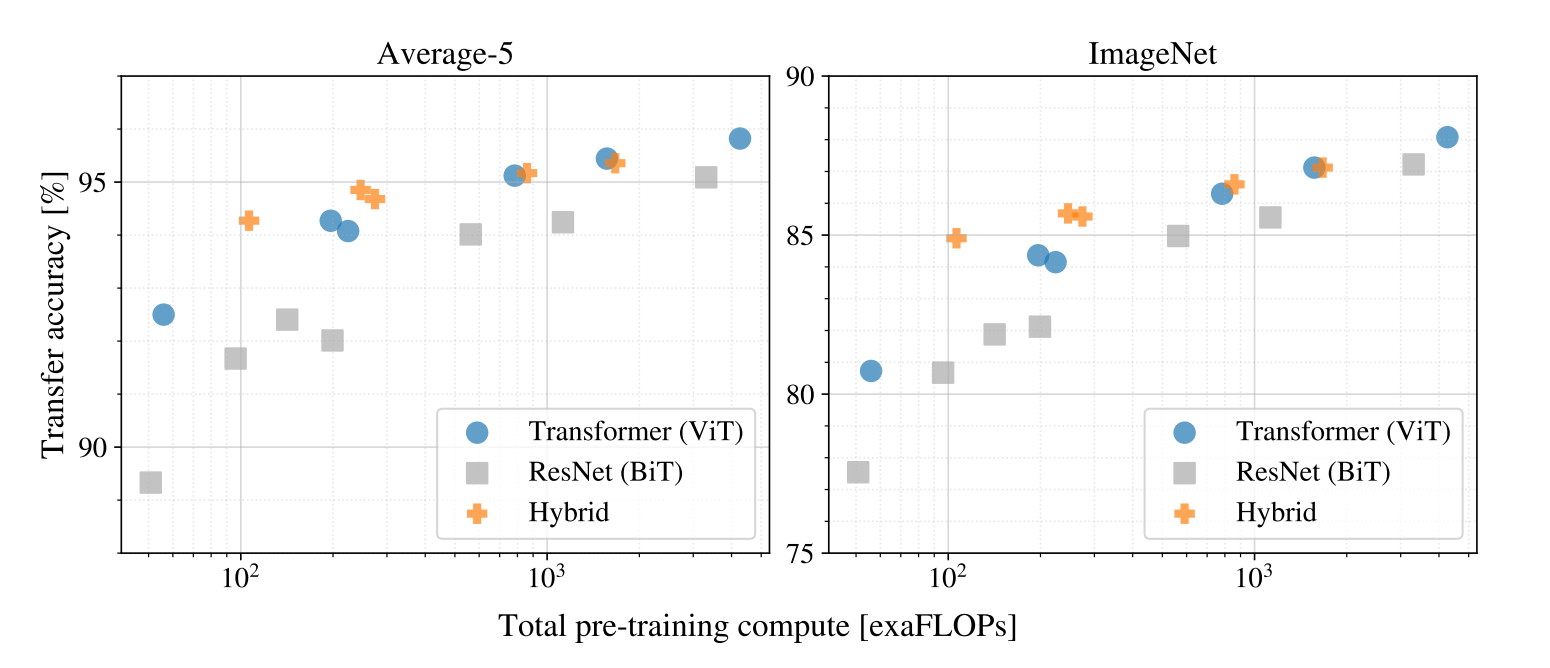
當在中型大小的資料集(e.g. ImageNet)上訓練,如果沒有 strong regularization,ViT 會略輸同等大小的 ResNets
這篇論文在更大的資料集(14M-300M 的影像)上訓練,就打敗了 inductive bias。在大量資料上作預訓練就很讚。
Related Work
大型的 Transformer-based 模型常常是先在大資料集上預訓練然後根據任務 fine-tune,比如 BERT 和 GPT。
要把 self-attention 用在 CV 上,最簡單的做法就是把每個 Pixel 當一個元素,但 self-attention 是平方複雜度,在現實的圖片很難應用。一個應用 Transformer 的做法是只把 self-attention 用在 local neighborhood,另外一個是用 Sparse Transformer,還有一堆特殊的方法,雖然表現不錯,但要用硬體加速起來不容易。
另一個有關的模型是 iGPT,在 reduce image resolution 和 color space 後把 transformer 應用在 image pixels 上。它用非監督式訓練後,再 fine-tune 或做 linear probing(只更新最後的 linear layer) 分類任務,表現很好。
已經有類似的工作了,抽取 patches of size 2 * 2,最後再接 full self-attention,基本上和 ViT 非常像,這篇論文進一步證明了作大規模的預訓練可以讓 Transformer 和 SOTA 的 CNN 相比,而且 ViT 因為 patch 比較大,可以處理 medium-resolution 的圖片。這問題是可預期的,因為 Transformer 缺少了一些 inductive biases。
- inductive biases
- 一些假設
- 比如 CNN 常有四個假設
- locality
- translation invariance with pooling layers
- 平移不變性
- translation equivariance
- f(g(x)) = g(f(x))
- 卷積和平移的先後順序沒差
Method
模型盡可能類似原始 Transformer,這樣可以把一些 NLP 上成功的 Transformer 架構拿來用,還可以用一些很有效率的 implementation
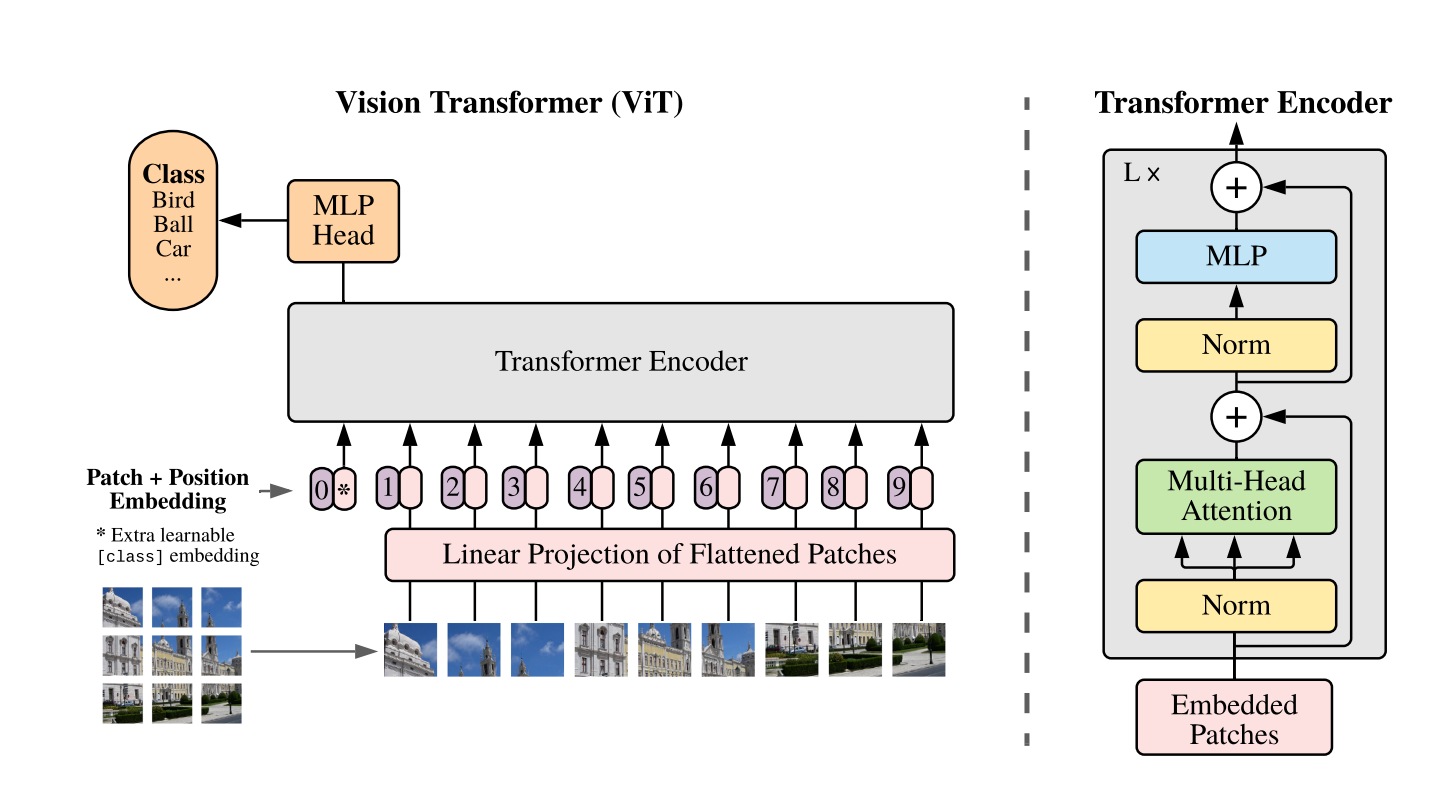
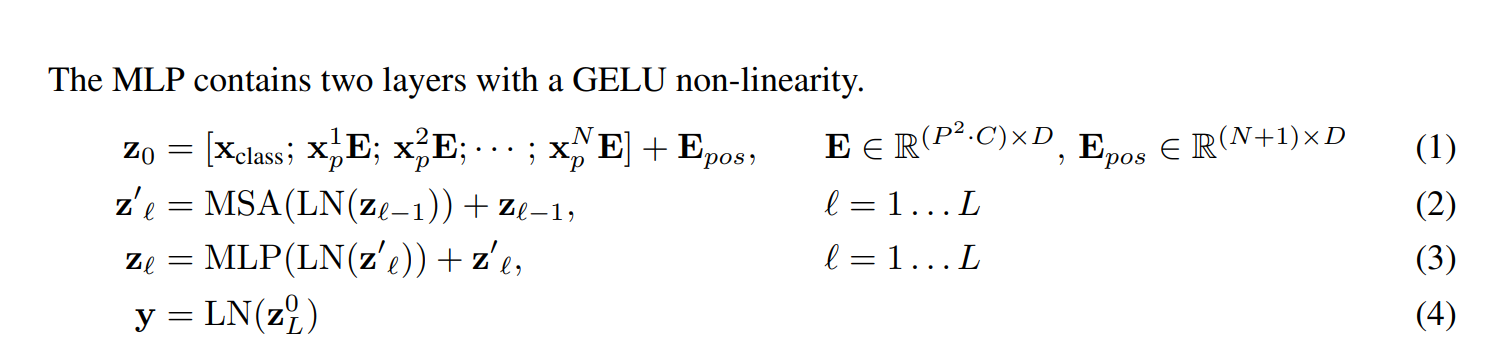
embedding 維度是 768 = 16 * 16 * 3 position embedding 的做法是 standard learnable 1D positional embeddings,就是 BERT 的做法,簡單來說就是生出一張可以訓練的表,(序列長度, embedding size),作者也有嘗試其他方法,但發現成效差不多,比如 2D positional embedding,概念就是從生出(序列長度, embedding size)變成生出 2 個(sqrt(序列長度), embedding size)。
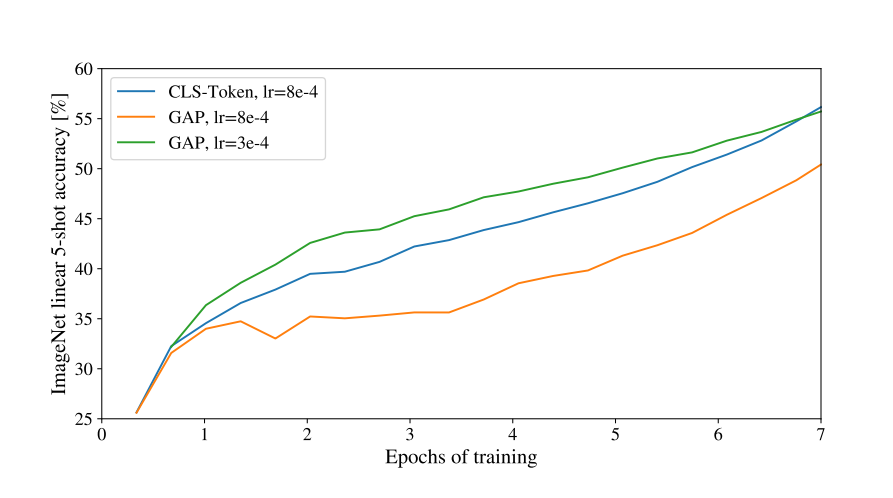
[class] 的概念是 NLP 出來的,ResNet-like 的架構常見的做法也有通過 globally average-pooling (GAP)來生出向量,再接上分類器做預測。實驗發現直接在 transformer 的輸出做 GAP 和 [class] 都可以達到不錯的效果。
Conclusion
拿標準的 Transformer 來作 Image recognition,和以往用 self-attention 在 CV 的方法不一樣,除了一開始的 initial patch extraction,沒有引入其他影像特有的 inductive biases。直接把圖片當成是一系列的 patch,然後直接用 Transformer encoder 當一般 NLP 任務處理。在很多影像分類訓練集上表現得更好還在 pre-train 上相對便宜。
還有一些值得挑戰的地方,比如把 ViT 應用在其他 CV 任務,比如 detection 和 segmentation。另一個挑戰是探索自監督預訓練的方法。這篇論文其實有實驗自監督,表現 OK,但和監督式還是有很大的落差。擴大 ViT 可能有更好的結果。