paper: Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Abstract
BERT 和 RoBERTa 在 semantic textual similarity (STS) 上太花時間,因為他需要將兩個句子都輸入網路,並且兩兩比對。
Sentence-BERT(SBERT) 對預訓練的 BERT 作了一些修改,透過 siamese 和 triplet network 的結構來生出有意義的 embeddings,使其最後可以透過 cosine-similarity 比較相似度。
Introduction
SBERT 使 BERT 可以用於某些迄今為止不適用於 BERT 的任務,比如 large-scale semantic similarity comparison、clustering 還有 information retrieval via semantic search。
以往的相關研究是把單個句子輸入 BERT,最後 average BERT output layer,或是使用第一個 output,但這樣會產生糟糕的 sentence embeddings。
SentEval 是一個 evaluation toolkit for sentence embeddings
Related Work
BERT 透過輸入兩個句子,以 [SEP] 隔開,可以在 STS 取得 SOTA。
但這樣無法計算獨立的 sentence embedding,所以過往的研究人員把單個句子輸入 BERT,最後 average BERT output layer,或是使用第一個 output。
Model
SBERT 在 BERT / RoBERTa 的輸出中添加了 pooling,作者嘗試了三種策略,CLS-token 的輸出、所以輸出向量的平均、max-over-time of the output vectors,默認是 MEAN。
實驗以下結構和目標函數:
-
Classification Objective Function

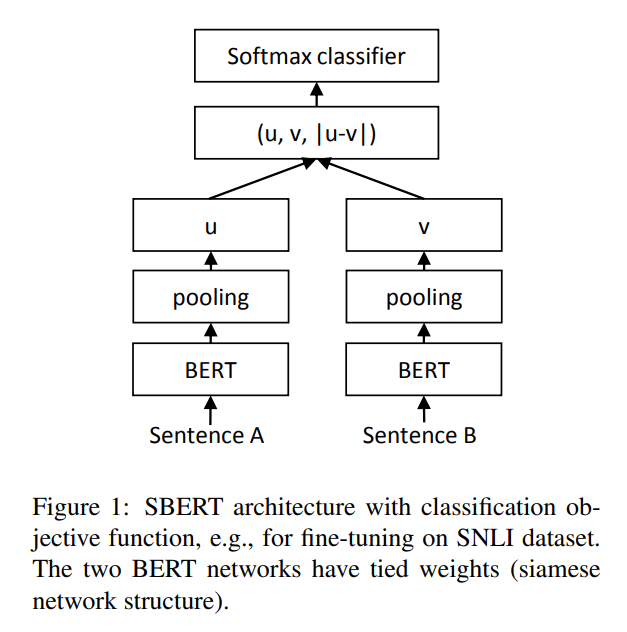
-
Regression Objective Function
-
用 mean squared-error loss
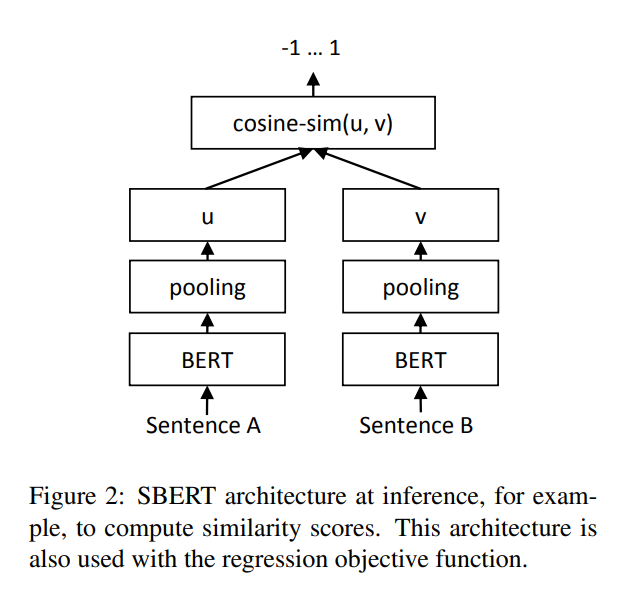
-
Triplet Objective Function

Training Details
- Dataset
- SNLI 結合 Multi-Genre NLI
- SNLI: 570,000 個 句子 pair,有三類,contradiction, eintailment, and neutral
- MultiNLI: 430,000 個句子 pair
- 3-way softmax Classification Objective Function
- 1-epoch
- batch-size: 16
- Adam
- lr: 2e-5
- warm-up: 超過 10% of the training data
- 默認 pooling 策略: MEAN
- SNLI 結合 Multi-Genre NLI
Evaluation
學習一個複雜的回歸函數分析 STS 常是 SOTA,但是由於他是 pair-wise,遇到 combinatorial explosion,不好拓展。
本文用 cosine-similarity 比較兩個 embeddings 的相似度,也用 negative Manhatten 和 negative Euclidean distances,但得到差不多的結果。
Conclusion
用 BERT 生出的 embeddings 不適合常見的相似度測量方法,比如 cosine-similarity。
本文提出 SBERT 改進,在 siamese / triplet 網路架構中微調 BERT。
用 RoBERTa 替換掉 BERT 並沒有什麼顯著改進。