paper: Self-Instruct: Aligning Language Model with Self Generated Instructions
Abstract
大型 “instruction-tuned” 語言模型 (經過微調好回應 instruction) 已經展現出在新任務上 zero-shot 的能力。
然而他們嚴重依賴人工編寫的指令,在數量、多樣性和創造力上都受到了限制,阻礙了模型的通用性。
作者介紹了 Self-Instruct 這個框架,可以透過自己生成的指令,來增強預訓練模型遵循指令的能力。
將作者的方法應用在 GPT3,在 SuperNaturalInstructions 獲得了比原始模型高 33% 的改進,與使用 private user data 和 human annotations 的 $InstructGPT_{001}$ 性能相當。
為了進一步評估,我們為新任務整理一組專家編寫的指令,並通過人工評估,顯示出使用 Self-Instruction 調整 GPT3 的性能大大優於使用現有公共指令資料集,只比 $InstructGPT_{001}$ 落後 5% 的差距。
Self-Instruct 提供一個幾乎 annotation-free 的方法,align 預訓練模型和 instructions,而且作者釋出了他們的大型合成資料集,以促進未來對 instruction tuning 的研究。
Introduction
最近的 NLP 文獻見證了「建構可以遵循自然語言指令的模型方面」的大量活動。
這些發展由兩個關鍵部分組成:
- 大型預訓練語言模型 (LM)
- 人工編寫的指令資料
PromptSource 和 SuperNaturalInstructions 是最近兩個著名的資料集。 他們透過大量手動註釋來收集指令,以建造 T0 和 T$k$-Instruct。
然而這過程代價高昂,而且由於大多數人往往生成的都是流行的 NLP 任務,使其未能涵蓋真正多樣的任務,也不能涵蓋各種描述任務的不同方式,因此多樣性受侷限。
鑒於這些限制,想要繼續提升 instruction-tuned models 的品質,需要幫 supervising instruction-tuned models 發展替代方案。
本文介紹了 Self-Instruct,這是一種 semi-automated 的過程,用模型自身的 instructional signals 對 pretrained LM 進行 instruction-tuning。
整個流程是一種 iterative bootstrapping algorithm,從手動編寫的 limited seed set 引導生成。
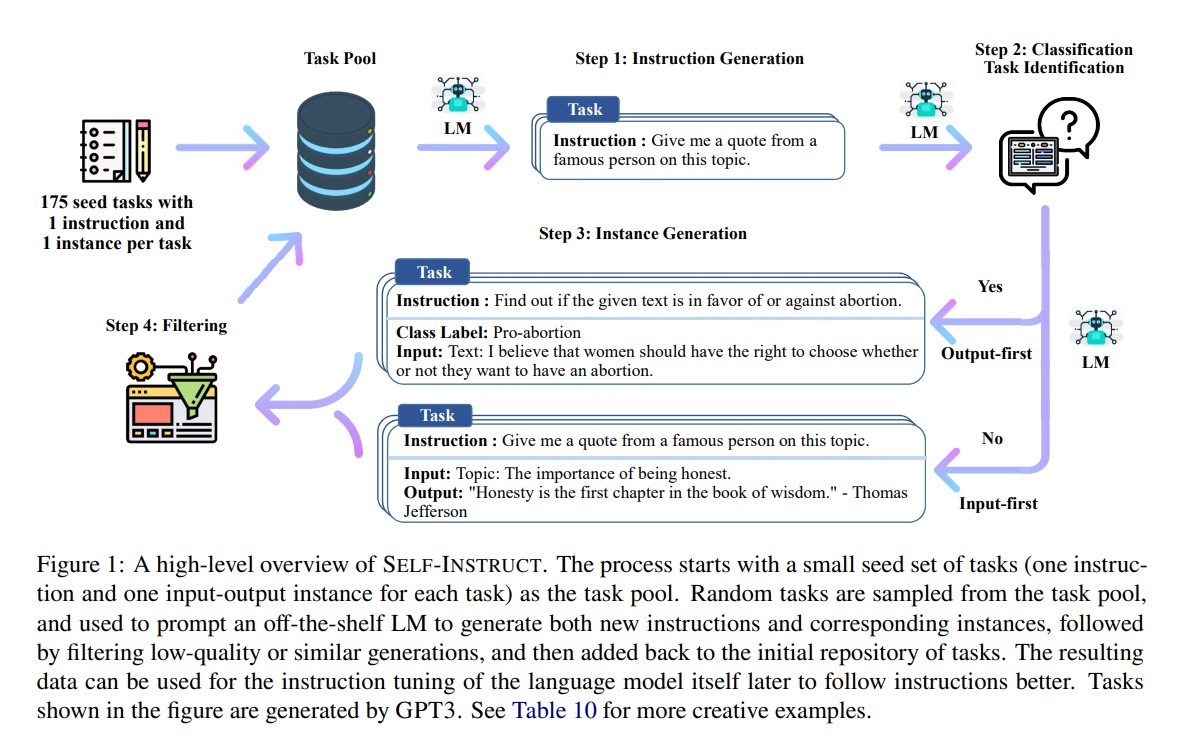
在第一階段,模型要幫新任務生成指令。 利用現有的指令集合,創建更廣泛的指令,好定義 (通常是新的) 任務。
對於新生成的指令集,框架為他們創建 input-output instances,稍後可以透過 supervising 用於 instruction tuning。
最後,透過各種手段,在低品質和重複的指令加到 task pool 前,把他們修剪掉。
可以重複這個流程非常多次,直到獲得大量任務。
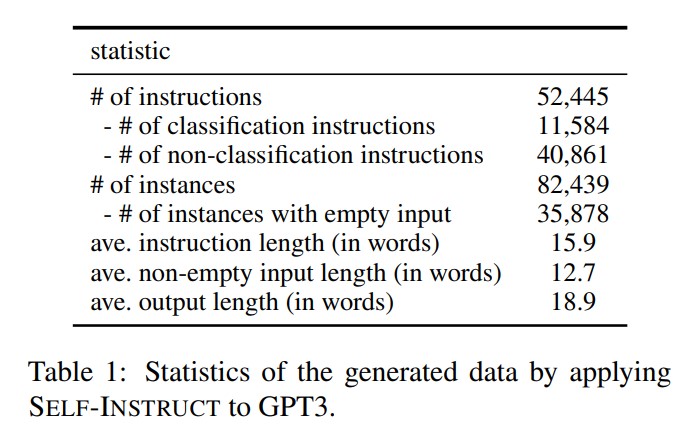
該模型的跌代過程中產生了大約 52K 個指令,與大約 85K 個 instance inputs 和 target outputs 配對 (有些相同的指令會對應多種輸入輸出)。
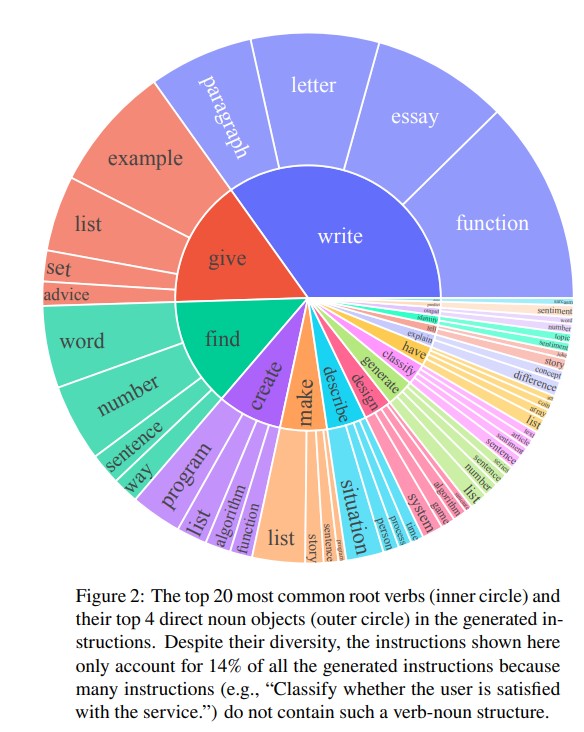
作者觀察到生成的資料提供了各種有創意的任務,其中超過 50% 的任務和 seed instructions 的 ROUGE-L overlap 小於 0.3。
基於上述結果,作者通過微調 GPT3 (和生成指令資料是同個模型) 建構了 $GPT3_{SELF-INST}$。
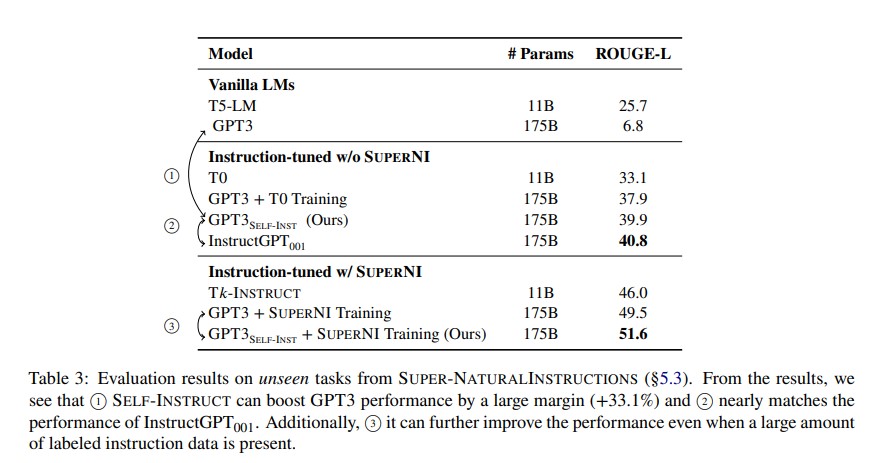
SuperNI 的結果表明,$GPT3_{SELF-INST}$ 性能大大優於 GPT3 (原始模型),高了 33.1%,幾乎和 $InstructGPT_{001}$ 的性能相當。
此外,作者在新創建的的指令集上進行人工評估,$GPT3_{SELF-INST}$ 顯示出廣泛的指令遵循能力,優於在其他公開可用指令數據集上訓練的模型,只比 InstrcutGPT001 落後 5%。
本文貢獻:
- Self-Instruct:一種用最少的人工標記數據引導指令遵循能力的作法
- 通過大量的 instruction-tuning 實驗,證明了有效性。
- 發布了一個包含 52K 指令的大型綜合資料集,還有一組手動編寫的新任務,用於建構和評估未來的 instruction-following models。
Related Work
Instruction-following language models
一系列工作顯示,使用 annotated “instructional” data,可以使普通語言模型遵循一般語言的指令。
也顯示出 “instructional” data 的大小和多樣性直接影響模型的泛化能力。
本文的工作目的在減少對人工註釋者的依賴。
Language models for data generation and augmentation
許多工作依賴生成式 LM 來生成數據或做 augmentation。
雖然作者的工作可被視為一種 augmentation,但和這些工作的差別在於不限於特定任務。
Self-Instruct 的一個明顯動機是引導出新的任務定義,而這些任務可能還未被 NLP 的研究者定義過。
Self-training
一種典型的 self-training 框架透過經過訓練的模型,幫 unlabeled 資料進行 label,然後用這些資料改進模型。
雖然 Self-Instruct 和 self-training 有一些相似之處,但多數 self-training 的方法都假設了一個特定的目標任務。
相比之下,Self-Instruct 從頭開始生出各種任務。
Knowledge distillation
這邊我想不太通為什麼可以和 Knowledge distillation 扯上關係
Knowledge distillation 通常涉及知識從較大模型到較小模型的轉移
Self-Instruct 也可以看做是 Knowledge distillation 的一種形式,但區別如下
- distillation 的來源和目標是相同的,即模型的知識被 distill 到他自己
- distill 的內容以 instruction task 的形式出現
Method
標記大規模指令資料對人類來說可能具有挑戰性,因為他需要
- 創意,好提出新任務
- 為每個任務編寫 labeled instances 的專業知識
Defining Instruction Data
我們要生成的指令資料集包含 {$I_t$},每個指令用自然語言定義了任務 $t$。
每個任務都有一個或多個 input-output instances ($X_t,Y_t$)。
給定 task instruction $I_t$,還有 instance x,模型 M 要生出 y:
$M(I_t,x)=y, for (x,y) \in (X_t,Y_t)$
值得注意的是,instance input 和 instruction 沒有嚴格分界。
比如 Instruction:“write an essay about school safety” x:"",可以被改為 Instruction:“write an essay about the following topic” x:“school safety”
Automatic Instruction Data Generation
生成指令資料的 pipeline 分成四個步驟:
- 指令生成
- 辨識指令是否是分類任務
- 用 input-first 或 output-first 做 instance generation
- 過濾掉低品質的資料
Instruction Generation
Self-Instruct 是基於一個發現,也就是大型語言模型可以透過 context 中的現有指令,生出新穎的指令。
為作者提供了一種從一小組人類編寫的指令中,使指令資料增長的做法。
作者用他們編寫的 175 個任務 (每個任務 1 個 instruction 和 1 個 instance) 初始化 task pool。
在每一個 step,作者從裡面 sample 8 個 instructions,作為 in-context 的範例。在這 8 個指令中,有 6 條來自人工編寫的任務,另外兩條來自前面步驟中模型生成的任務,以促進多樣性。
Classification Task Identification
因為對於分類和非分類的任務,作者會採取兩種做法,所以作者使用來自 seed taks 的 12 條分類指令和 19 條非分類指令,讓 GPT3 透過 few-shot 來判別。
Instance Generation
給予指令和他們的任務類別,作者獨立地為每條指令生成 instance。
這具備挑戰性,原因在於他需要模型瞭解目標任務是什麼,根據指令找出需要那些額外的輸入內容,並生成他們。 (模型要根據 instruction 生出 instance input)
作者發現,在 prompt 中放入其他包含 instruction-input-output 的任務範例的時候,模型可以實現這點。
一種自然的方法是 Input-first Approach,可以要求語言模型先根據指令提出 input,再生出相應的 output。
然而,這種方法在分類任務上,可能會偏向於生成某種 label。所以,對於分類任務,作者採用 Output-first Approach,先生成可能的 label,在每個 label 上再生成輸入。
Filtering and Postprocessing
為了鼓勵多樣性,只有當新的指令和任何現有的指令的 ROUGE-L overlapping 小於 0.7 的時候,才會被添加到 task pool。
還排除了一些包含了通常不能被 LM 處理的關鍵字 (e.g. images, pictures, graphs) 的指令。
在為每個指令生成新的 instance 的時候,會過濾掉完全相同或者是輸入相同但輸出不同的 instance。
Finetuning the LM to Follow Instructions
在創建大規模指令資料後,用這些資料對原始語言模型進行 fine-tune。
為此,將 instruction 和 instance input 連接起來,作為 prompt,然後訓練模型透過標準的監督式學習進行微調。
為了讓模型對不同的格式 robust,使用多個模板將指令和輸入 encode 在一起。
例如,指令可以有或沒有 Task: 前墜、輸入可以有或沒有 Input: 前墜,或是中間可以有不同數量的換行之類的。
Self-Instruct Data from GPT3
作者透過 OpenAI API 訪問最大的 GPT3 (davinci)
Statistics
Diversity
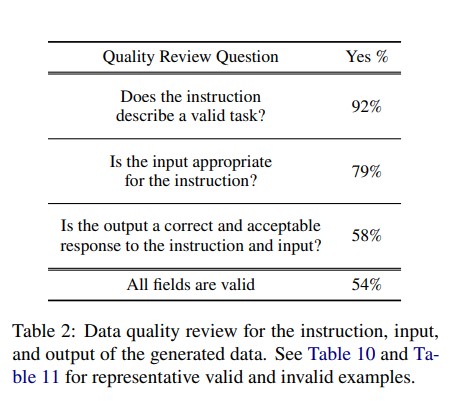
Quality
Experimental Results
$GPT3_{SELF-INST}$: fine-tuning GPT3 on its own instruction data
使用生出來的指令資料,對 GPT3 進行微調。
微調是透過 OpenAI finetuning API
Baselines
Off-the-shelf language models
T5-LM 和 GPT3 是普通 LM baselines (只有 pre-training,沒有額外 fine-tune)
這些 baseline 將表明現成的 LM 在預訓練後,能夠立刻自然地遵循指令的程度。
Publicly-available instruction-tuned models
T0 和 $T_k$-Instruct 是兩個 instruction-tuned models。
兩者都是從 T5 進行微調的,對這兩種模型,都使用具有 11B 參數的最大版本。
Instruction-tuned GPT3 models
作者評估了 InstructGPT,它是 OpenAI 基於 GPT3 開發的。
對於 SuperNI 的實驗,只與 text-davinci-001 engine 進行比較,因為更新的 engine 用最新的用戶資料,而且很可能已經看過 SuperNI。
對於新編寫的指令,評估時則包含了 001、002 和 003,以確保完整性。
為了進一步比較 Self-Instruct 在其他公開可用的指令訓練集資料,使用 PromptSource 和 SuperNI 的資料微調 GPT3,這些資料用於訓練 T0 和 $T_k$-Instruct 模型。
分別簡稱為 T0 訓練和 SuperNI 訓練。
Experiment 1: Zero-Shot Generalization on SUPERNI benchmark
首先以 zero-shot 的方式評估典型 NLP 任務遵循指令的能力。
Results
Experiment 2: Generalization to User-oriented Instructions on Novel Tasks
盡管 SuperNI 在現有的 NLP 任務具有全面性,多數的這些任務是初於研究理由提出的,而且偏向分類。
為了更好的獲取指令遵循模型的實用價值,作者中的一部分人策劃了一組面向用戶應用的新指令集。
他們先針對 Large LM 可能可以應用到的領域進行 brainstorm,並且制定與每個領域相關的 instruction 和 instance。
總共創建了 252 條指令,每條指令有 1 個 instance。
Human evaluation setup
評估模型在這些不同任務的測試集上的表現極具挑戰性,因為不同的任務需要不同的專業知識。
為了獲得更忠實的評價,作者請了 instructions 的作者對模型的預測結果進行評估。
實施一個 four-level rating system:
- Rating A
- 回覆有效且令人滿意
- Rating B
- 回覆可接受,但存在可以改進的地方
- Rating C
- 回覆相關,但在內容上有重大錯誤
- Rating D
- 回覆不相關或無效,包含重複輸入的部分,完全無關的輸出。
Results
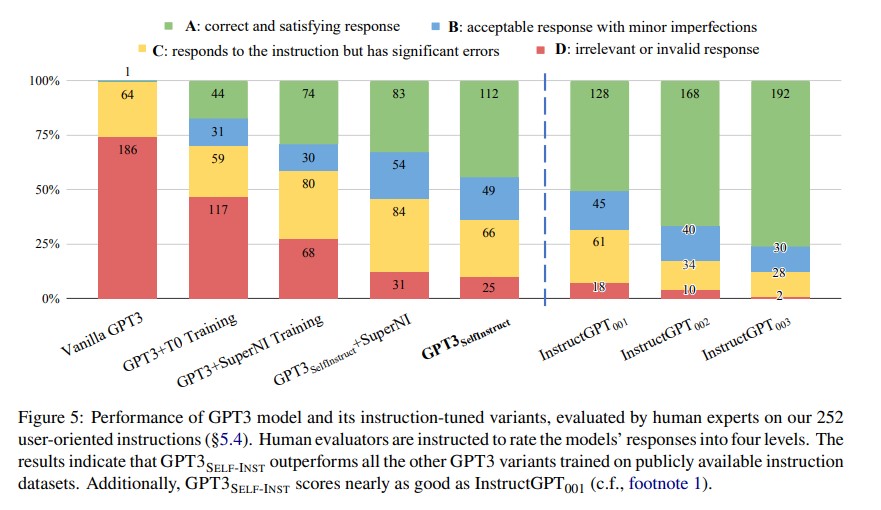
如果把 Rating B 以上視為有效,$GPT_{SELF-INST}$ 只和 $InstructGPT_{001}$ 相差 5%
Discussion and Limitation
Why does SELF-INSTRUCT work?
值得反思的是,在最近成功的 instruction-tuning LMs 中,高品質的 human feedback 扮演的角色。
這裡有兩個極端的假設:
-
Human feedback 是 instruction-tuning 中必要且不可或缺的角色,因為 LM 需要了解在預訓練過程中沒完全了解到的問題。
-
Human feedback 是 instruction-tuning 一個可選的方向,因為 LM 在預訓練就已經很熟悉指令了。
雖然現實可能介於這兩個極端之間,作者推測可能更傾向於第二種假設,尤其是對於較大的模型。
第二種,也是人類直覺,是 Self- Instruct 的關鍵動機,而且也從成功的結果獲得支持。
Broader Impact
除了本文的直接關注點外,作者相信 Self-Instruct 可能有助於揭露各種 instruction tuning 模型 “幕後” 發生的事情。
不幸的是,由於他們的資料集尚未發布,這種業界模型仍處於 API 牆之後。
人們對其結構以及為何能展現令人印象深刻的能力知之甚少。
Limitations of Self-Instruct
Tail phenomena
Self-Instruct 依賴於 LM,繼承 LM 的所有限制。
最近的研究顯示出 tail phenomena 對 LM 的成功構成嚴峻的挑戰。
換句話說,LM 的最大收益出現於語言中最頻繁出現的部分 (語言分佈的頭部),而低頻率出現的上下文中獲得的收益最小。
同樣的,在這項工作背景下,如果 Self-Instruct 大部分的收益偏向預訓練 corpus 中頻繁出現的任務或指令,那也不令人感到意外。
因此,該方法在不常見和有創意的指令下,可能會顯現出脆弱性。
Dependence on large models
因為 Self-Instruct 依賴於從 LM 中提取初的 inductive bias,因此它可能適合 larger model。
如果這是對的,這會對那些沒有大量計算資源的人造成阻礙。
Reinforcing LM biases
作者擔心這種迭代作法可能會產生意料之外的結果,比如將有問題的社會偏見放大。