paper: RoBERTa: A Robustly Optimized BERT Pretraining Approach
|
|
Abstract
發現 BERT 訓練不足,並且作者的模型在 4/9 的 GLUE 任務, RACE 和 SQuAD 取得 SOTA。
Introduction
自監督的訓練方法帶來了顯著的性能提升,但要確定這一堆方法中的哪些方面貢獻最大,具備挑戰性。
訓練的計算量是昂貴的,使 fine-tune 受限,而且通常都是用不同大小的 private training data,使評估模型更加困難。
作者提出了對 BERT 預訓練的 replication study,包括對超參數的調整,以及對訓練集大小的仔細評估。
作者發現 BERT 訓練不足,並提出了一種改進方法,稱為 RoBERTa,可以達到或超過所有 post-BERT 的方法。
修改如下:
- 訓練模型的時間更長,batch 更大,用更多 data
- 移除 next sentence prediction objective
- 訓練更長的序列
- 動態地改變用於訓練資料的 masking pattern
貢獻:
- 提出一組重要的 BERT 設計選擇和訓練策略
- 使用了新的 dataset,叫做 CCNEWS,並證明用更多的資料來預訓練,可以提高下游任務的表現
- 訓練表明,在正確的設計選擇下,pretrained masked language model 和其他最近的方法比,具有競爭力
Background
對 BERT 做回顧
Architecture
- L layers
- A self-attention heads
- H hidden dimension
Training Objectives
預訓練的時候,BERT 有兩個目標: masked language modeling 和 next sentence prediction
Masked Language Model (MLM)
BERT 隨機選擇 15% 的 token 進行可能的替換
80% 換成 [MASK],10% 保持不變,10% 被選為一個隨便的 vocabulary token
Next Sentence Prediction (NSP)
分類第二句是不是下一句,是二元分類。
正例由提取連續的句子產生,負例由不同的片段配對產生。
正例和負例以相等機率產生。
Optimization
- Adam
- $\beta_1$ = 0.9, $\beta_2$ = 0.999, $\epsilon$ = 1e-6
- $L_2$ weight decay of 0.01
- Learning rate 前 10,000 step warm up 到 1e-4,然後 linear decay
- 全部的 layer 和 attention weight 都 dropout 0.1
- GELU 激活函數
- 1,000,000 次 update,batch size 256,序列長度 512
Data
BERT 在 BookCorpus 和 English Wikipedia 混和的資料集上訓練,共有 16GB 的未壓縮文本
Experimental Setup
描述對於 BERT 的 replication study 的實驗設置
Implementation
作者用 FAIRSEQ 重新實現了 BERT。
主要遵循 [Background-Optimization] 中的 BERT 原始超參數,但 peak learning rate 和 warmup step 除外,他們針對每個設置單獨調整。
作者發現訓練對 Adam epsilon 非常敏感。
作者發現設置 $\beta_2$ = 0.98,在大 batch size 的情況下,可以提高訓練時的穩定性。
用最多 512 個 token 預訓練。
作者不會隨機注入短序列,也不會為前 90% 的更新縮短輸入的長度。
作者只訓練 full-length 的 sequences。
Data
BERT-style 的預訓練仰賴大量文本。
已有研究證明增加數據量可以提高 end-task 的性能。
已有一些研究,用比原始 BERT 更多樣更大的數據集,但不是所有的數據集都有公開。
本研究用了五個不同大小和領域的英文文本,共有超過 160 GB 的未壓縮文本。
使用以下數據集:
- BookCorpus + English Wikipedia
- BERT 原本使用的。
- 16 GB
- CC-News
- 作者從 CommonCrawl News dataset 的英文部分中蒐集,包含了 2016 年 9 月到 2019 年 2 月的 6300 萬篇英文新聞。
- 過濾後有 76 GB
- OpenWebText
- WebText 的開源重建版,從 Reddit 上至少有 3 個 upvotes 的 shared URLs 提取出的 Web 內容。
- 38 GB
- Stories
- 包含 CommonCrawl data 的一個子集合,經過過濾,以匹配 story-like style of Winograd schemas
- 31 GB
Evaluation
使用以下三個 benchmarks 評估預訓練模型
GLUE
-
The General Language Understanding Evaluation
-
用於評估自然語言理解的 9 個數據集的集合,任務被定義為 single-sentence 分類或 sentence-pair 分類任務。
-
finetune 的流程遵循原始 BERT paper
SQuAD
-
The Stanford Question Answering Dataset
-
提供一段 context 以及一個問題
-
具有兩個版本 V1.1 和 V2.0
- V1.1
- context 總是包含一個答案
- 評估 V1.1 的時候,作者採用和 BERT 相同的 span prediction method
- V2.0
- 一些問題在提供的 context 中沒有回答,使任務更有挑戰性
- 評估 V2.0 的時候,作者會用一個額外的二元分類器預測問題是否可以回答,在評估的時候,只預測被分類為可回答的
- V1.1
RACE
- The ReAding Comprehension from Examinations
- 大型閱讀理解數據集,有超過 28,000 篇文章 以及將近 100,000 個問題
- 從中國的英文考試蒐集的,這些考試是為國中生和高中生設計的
- 每篇文章都與多個問題相關聯
- 對每個問題,要從四個選項中選出一個對的
- context 比起其他閱讀理解的數據集要長,而且要推理的問題比例很大
Training Procedure Analysis
探討哪些選擇對成功預訓練 BERT 很重要。
作者把架構固定,也就是訓練和$BERT_{BASE}$ (L=12, H=768, A=12, 110M params)一樣架構的 BERT models
Static vs. Dynamic Masking
BERT 在 preprocessing 的時候處理 masking,產生單個 static mask。 作者為了避免在每個 epoch 都對每個 instance 用相同的 mask,將數據複製了 10 次,在 40 個 epochs 裡,以 10 種不同的方式 mask。所以一次訓練過程中,相同的 mask 會出現四次。
作者會以上述策略和 Dynamic masking 進行比較,Dynamic masking 是在每次餵 model 前,才生成 mask。
作者發現 Dynamic Masking 相比 static,要不是差不多,就是略好,基於結果和效率的優勢考量,其他實驗中都用 dynamic masking。
Model Input Format and Next Sentence Prediction
原始的 BERT 預訓練中,兩個句子要不是同一個文件的連續句子(p = 0.5),不然就是不同的 document 做採樣
以往有研究指出移除 NSP 會損害性能,但也有研究質疑必要性,所以本文比較了幾種替代訓練格式:
- SEGMENT-PAIR+NSP
- 最原始的方法,每個 segment 可以有多個自然句子
- SENTENCE-PAIR+NSP
- 只包含一對句子,由於輸入明顯少於 512 token,所以會增加 batch size 讓 token 總數和前者差不多
- FULL-SENTENCES
- 包含從一個或多個文件中連續採樣的完整句子,可能會跨越文件邊界,在文件邊界間會加個額外的分隔符
- 移除了 NSP
- DOC-SENTENCES
- 和 FULL-SENTENCES 差不多,但不能跨越 document,在 document 尾巴的部分會容易少於 512,所以會動態增加 batch size,讓 token 總數和 FULL-SENTENCES 差不多
- 移除了 NSP
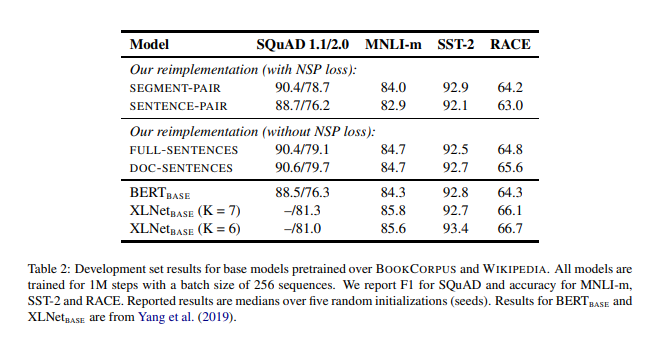
發現 DOC-SENTENCES 是最棒的,但由於 DOC-SENTENCES 會讓 batch sizes 大小可變,所以其他實驗會用 FULL-SENTENCES,比較好和其他相關工作比較。
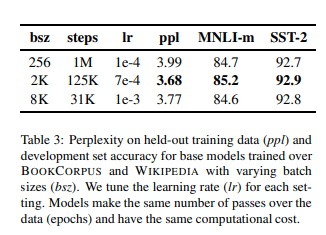
Training with large batches
根據過去神經網路機器翻譯的工作,當 learning rate 適當增加的時候,用非常大的的 mini-bathces 可以提高 optimization 的速度和 end-task 性能。
最近的研究也顯示 BERT 適用於 large batch training。
Text Encoding
Byte-Pair Encoding (BPE) 是一種介於字符級別和詞級別表示之間的混合表示方法,它允許處理自然語言語料庫中常見的大詞彙量。
BPE 不依賴於完整的單詞,而是依靠 subwords units,通過對訓練語料進行統計分析來提取這些 subwords units。
BPE 詞彙表的大小通常在 10K-100K 的 subword units。
在 “Language Models are Unsupervised Multitask Learners” 文中,提到了一種巧妙的 BPE 實現,不是用 unicode characters,而是用 bytes 作為 base subword units。可以生出 50K 大小的詞彙表,而且不用引入任何的 “unknown”。
原始的 BERT 用 character-level BPE vocabulary,大小為 30K。
本文考慮用 50K byte-level BPE vocabulary,而不對輸入做額外的 preprocessing 或 tokenization,“Language Models are Unsupervised Multitask Learners” 的研究顯示這些 Encoding 的方法在最終效能上並無太大差別,只在某些任務上 end-task performance 表現稍差。
但作者相信 universal encoding scheme 的優勢超過了輕微的性能下降,其他實驗也會用這種邊碼方式。
RoBERTa
整理上面說的改進。
RoBERTa 用以下配置:
- dynamic masking
- FULL-SENTENCES without NSP loss
- large mini-batches
- larger byte-level BPE
此外,還調查了兩個之前的工作沒強調的重要因素:
- 用於預訓練的 data
- 訓練過 data 的次數
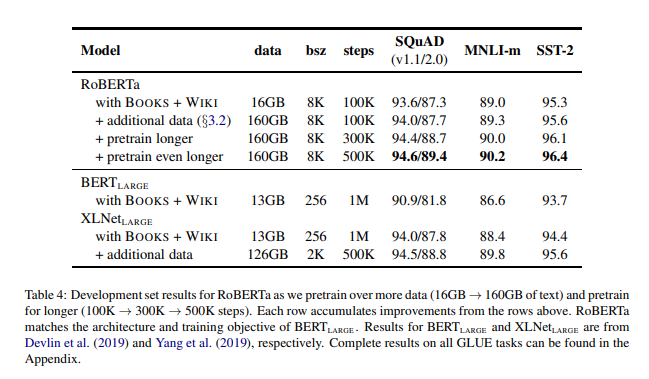
為了把這些因素的重要性和其他模型選擇分隔開,先按照 $BERT_{LARGE}$ (L = 24, H = 1024, A = 16, 355M parameters) 訓練 RoBERTa。
作者在 BOOKCORPUS plus WIKIPEDIA dataset 進行了 100K step 的預訓練。
在控制 training data 的情況下, RoBERTa 比 $BERT_{LARGE}$ 的結果有大幅度的改進,重申了前面設計選擇的重要性。
接下來,結合之前說的額外 dataset,並用相同的步數(100K) 訓練 RoBERTa,觀察到下游任務的性能進一步提高,驗證了數據大小和多樣性的重要性。
最後,對 RoBERTa 做更長時間的預訓練,將步數提高到 300K 和 500K,再次觀察到下游任務性能顯著提升。
作者也注意到,即使是他們訓練時間最長的模型,也不會 overfit 他們的數據。
本文的其他部分在三個 benchmark 評估好壞: GLUE、SQuaD 和 RACE
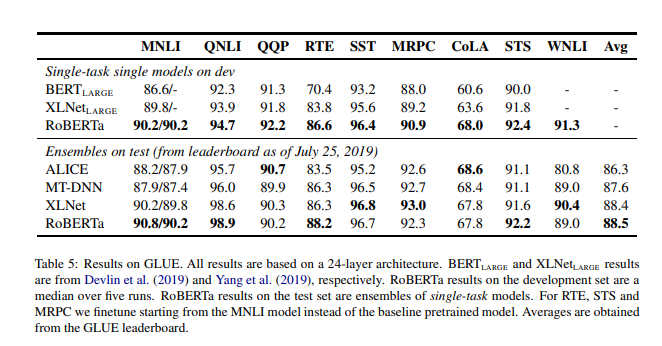
GLUE Results
雖然很多 GLUE 排行榜的提交都是 depend on multi-task finetuning,但作者的 submission 是 depends only on single-task finetuning。
此外,對於 RTE、STS 和 MRPC,從 MNLI 的模型微調會比 baseline 的 RoBERTa 有幫助許多。
在第一個設置 (single-task, dev) 中,RoBERTa 在所有 9 個 GLUE 任務 dev set 上都取得了最先進的結果。
在第二個設置 (ensembles, test) 中,作者將 RoBERTa 提交到 GLUE 排行榜,並在 9 個任務中的 4 個上取得了 SOTA 和迄今為止的最高平均分。
這令人興奮的地方在於,與多數 top submissions 不同,RoBERTa 不是 depend on multi-tasking finetuning
Conclusion
在預訓練 BERT 模型時,作者仔細評估了許多設計決策。
作者發現,通過對模型進行更長時間的訓練、使用更大的批次處理更多的數據、去除 NSP、訓練更長的序列、dynamic masking,可以顯著提高性能。
作者改進的預訓練程序,我們稱之為 RoBERTa,在 GLUE、RACE 和 SQuAD 上實現了 SOTA,而無需為 GLUE 進行多任務微調或為 SQuAD 提供額外的數據。
這些結果說明了這些以前被忽視的設計決策的重要性,並表明 BERT 的預訓練目標與最近提出的替代方案相比仍然具有競爭力。