Abstract
本研究提供了一個計算 patent-to-patent (p2p) technological similarity 的有效方法。
並提出一個 hybrid framework,用於把 p2p 相似性的結果應用於 semantic search 和 automated patent classification。
把 Sentence-BERT (SBERT) 用在 claims 上來作 embeddings。
為了進一步提升 embedding 的品質,使用基於 SBERT 和 RoBERT 的 transformer model,然後再用 augmented approach 在 in-domain supervised patent claims data(相對於 out-domain) 來 fine-tune SBERT。
用 KNN(Nearest Neighbors) 來根據 p2p similarity 分類模型。
Introduction
傳統上的 p2p 相似度是基於關鍵字、技術類別等 metadata 決定的,但近期 semantic-based 的方法也越來越受歡迎。
- 目前遇到的問題
- BERT 用來計算 p2p 相似性的成本很高
- 基於 generic text 的 pre-trained model 在遇到特定領域的專業術語時可能會遇到侷限。
- 在專利做 multi-label classification (MLC) 是個挑戰
- 貢獻
- 提供一個快速高效的框架,利用 Transformer 架構計算 p2p 相似度
- 透過 augmented SBERT,將 transformer model fine-tune 到 domain-specific language
- 提出一個基於 Transformer 和 傳統 ML 模型的混和架構,可以打敗 multi-label 和 multi-class 的專利分類 SOTA 模型
- 用簡單的 KNN 進行專利分類,提供了一種簡單的方法來檢查、理解和解釋模型的預測結果
Data
Dataset Description
本研究使用 PatentsView dataset,PatentsView 平台建立在一個定期更新的 database 上。
dataset 已用於之前類似的研究,比如 DeepPatent、PatentBERT。
本研究使用了 2013-2017 的所有專利,這些專利至少要在 BigQuery 上有一條 claim。
本研究的 record 有 1,492,294 項專利,並用 8% 作為測試集。
此外,本研究刪除了有重複專利 ID 和 claim text 的 record。
Textual Data: Patent Claims
本研究使用 claim 作為輸入。
claim 被認為是準備專利文件的初始框架,其他文件都是根據 claim 準備的, 因此,claim 比其他文件包含更全面和準確的訊息。
claim 具有層次結構,first claim 被視為該架構的主幹。
本研究僅使用 first claim,但在以後的研究中,希望根據 tree structure 組合所有 claim,並計算 semantic similarity,並做多標籤分類。
在研究樣本中, claim 平均有 17 個。
claim 的平均長度是 162,本研究中,BERT 的 max_seq_length 是 510。
Patent Classification: CPC Classes
CPC系統和IPC(國際專利分類)系統是最常用的兩種分類系統,CPC 是 IPC 系統的更具體和詳細的版本。
CPC 具有用於分類的層次結構,包括 Section、Class、Subclass 和 Group, 在子類級別,CPC 有 667 個標籤。
在數據集中我們有 663 個標籤,其中 159 個在數據集中的樣本少於 350 個,這種標籤分佈導致了 KNN 不好處理,一般來說,隨著 instance 數量的增加,我們可以提高模型的準確性。
Method and experimental setup
Pretrained Language Models (LMs) 在 NLP 中變得十分流行。
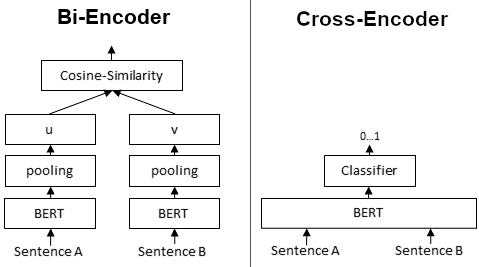
在 pairwise sentence semantic similarity,SBERT 和 BERT 是兩種具有顯著不同效果的方法。
BERT 通常可以取得更好的性能,但在實際應用上來說太慢了。
SBERT 在實際應用上表現還行,但需要 in-domain training data 並且 finetune。
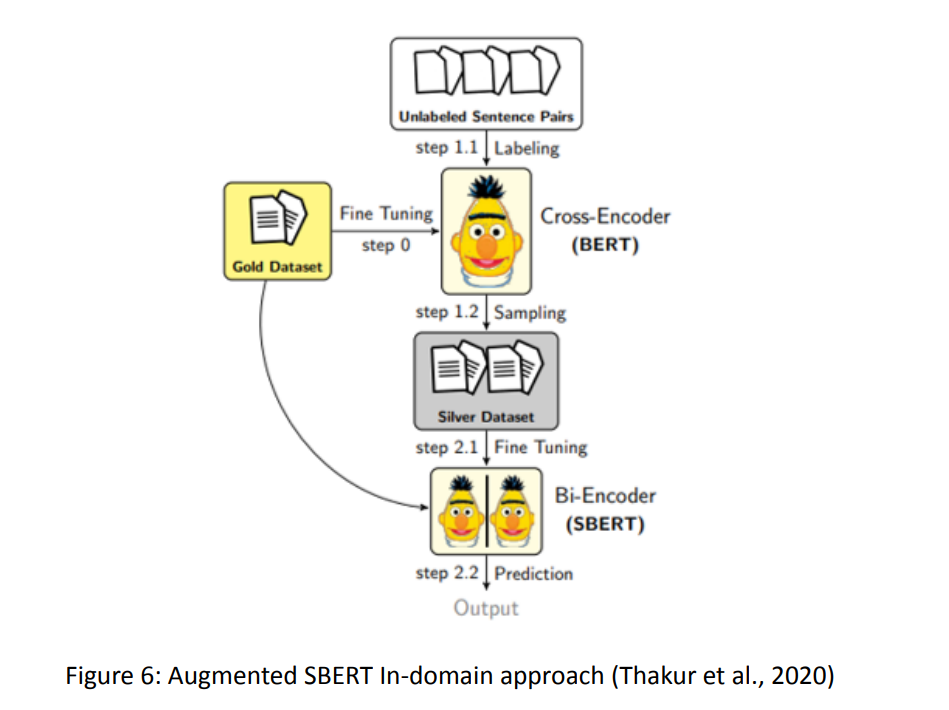
上圖是 Augmented SBERT In-domain approach。
in-domain sentence pairs 透過 cross-encoder 來標記,假設有 n 個 in-domain sentences,會有 $C_2^n$ 組可能的組合。
使用所有可能的組合並不會提高性能,所以要有正確的採樣策略,才可提升性能的同時也減少計算開銷。
上圖那種結合 cross-encoder 和 bi-encoder 的作法被稱為 Augmented SBERT (AugSBERT), 涉及以下三個步驟:
- 用資料集 Fine-tune RoBERTa 以生出 cross-encoder
- 用 cross-encoder 來把未標記的資料標記,同時基於某種特定的採樣策略,從 652,653 種可能的組合中挑選 3432 組
- 把資料集 + 額外的 3432 組資料一起拿來訓練 SBERT
Results
P2P similarity and semantic search
Patent Semantic Search (PSS) 是專利分析的基礎部分。
Transformer 模型等語義相似性的解法是一種新解法,可以用來解決基於關鍵字的搜尋方法中, query terms 和專利內容不匹配的問題。
為了評估模型的準確性,未來的研究中,作者希望通過 Mean Reciprocal Rank (MRR) 來評估分類結果。
CPC Prediction
Top-N 準確度等於 GT 與預測有最高概率的任何 N 個預測匹配的頻率, 所以 Top-5 就是最高的五個分類中一個就有中。
Conclusion
本文使用 augmented SBERT 獲得 SOTA 的專利文本 embedding。
介紹了一種 augmented 的方法,把 SBERT 微調到適合 patent claims 的 domain。
SBERT 的一個主要優點是可以有效率地獲得 embedding distance,使我們能夠為大的專利資料集建構 p2p similarity。
雖然基於文本的 p2p similarity 的有用性已經在各種應用方面得到證明,但本文進一步證明作者的 transformer-based p2p similarity 可以被用在 SOTA 的專利分類。
而且使用簡單的 KNN 方法,檢查他們可以使模型決策具備 understandable 和 explainable。
Limitations & Future Research
未來希望用 Annoy(Approximate Nearest Neighbor Oh Yeah!) 來測試更大樣本的模型並比較結果。
Annoy(Approximate Nearest Neighbor Oh Yeah!) 是想尋找近似相似而不是精確相似的句子。