paper: PatentBERT: Patent Classification with Fine-Tuning a pre-trained BERT Model
Abstract
把 fine-tune BERT 應用在專利分類上,當應用於超過 200 萬件專利的資料集時,該方法超越了結合 word-embedding 的 CNN 的 SOTA 作法。
- 貢獻:
- 一個用預訓練的 BERT 去 fine-tune 的 SOTA 方法
- 一個叫做 USPTO-3M 的大型資料集,屬於 CPC subclass level,並提供 SQL 語句讓後續的研究者使用
- 與傳統觀念相反,只需要 claim 就足以完成分類任務
Introduction
專利分類是一個 multi-label 的分類任務。
由於標籤的數量可能很大,所以是個具有挑戰性的任務。
作者準備了一個基於 CPC 的新資料集,有超過三百萬項美國專利。
- CPC
- Cooperative Patent Classification
- 是 IPC 更具體和詳細的版本
- 可預見將取代 IPC 成為新的標準
- 只是由於 CLEP-IP 競賽,大部分論文都基於 IPC
- 資料集包含 1978 到 2009 提交的專利
- 只是由於 CLEP-IP 競賽,大部分論文都基於 IPC
- IPC
- International Patent Classification
此外,作者的 dataset 基於 patent claims
- patent claims
- 重要性在過往被低估
- 在起草專利申請時,專利業者會先起草 patent claims
- 專利文件的其餘部分由 claim 做延伸
- 在專利法中,claims 定義了專利發明的界線,確定了專利權範圍
為使模型更簡單,只關注 patent claims,並且僅用第一項 claim。
相關工作
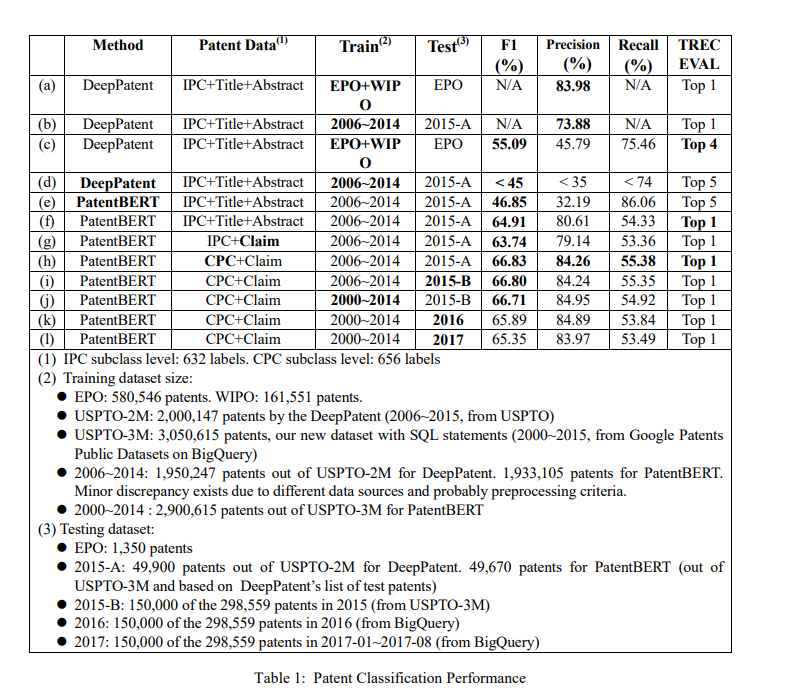
過往有些研究只顯示了 precision,但沒有 F1 value 或 recall,難以公平比較。
以 DeepPatent
Data
過往資料基於 CLEF-IP 或 patent offices。
作者發現在 BigQuery 用 Google Patents Public Datasets 更容易。
而且可用 SQL statements,作者認為比共享傳統資料集更好,原因如下:
- Seperation of concerns
- 如果資料包含前處理或後處理,其他研究人員需要不同操作時會很頭痛。
- Clarity and flexibility
- SQL statement 精確且容易根據不同條件進行修改。
在和 DeepPatent 比較的時候,可以的話,會用 USPTO2M 進行測試,如果不行,才會合併來自 USPTO-3M 的資料,比如 USPTO-2M 沒有 claims 的情況。
為了比較 claim 如何影響性能,將合併兩個資料集。
Method & Experimental Setup
用 BERT-Base 就可以打敗 DeepPatent。
遵循 BERT Project 中給的 fine-tune 範例。
為了 multilabel,用 sigmoid cross entropy with logits function 而不是用 softmax。
Conclusion
專利分類作為具有挑戰性的任務,幾十年來一直沒有令人滿意的表現。
本文提出一個基於 fine-tune BERT 的方法,性能優於 DeepPatent。
並且結果表明只用 patent claim 就可以完成分類任務。