paper: Latent Retrieval for Weakly Supervised Open Domain Question Answering
Abstract
最近的工作常依賴於兩個假設,一個是對 supporting evidence 做 strong supervision,另一個是假設 blackbox information retrieval (IR) system 可以找到所有的 evidence candidates
作者認為兩者都不是最理想的,因為 gold evidence 不總是可用,而且 QA 和 IR 有著根本上的不同
作者首次證明,在沒有任何 IR 的情況下,可以從 question-answer pair 中共同學習 retriver 和 reader
在這種 setting 下,來自 Wikipedia 的 evidence retrieval 被視作 latent variable
由於 learn from scratch 不切實際,因此用 Inverse Cloze Task (ICT) 來預訓練 retriever
作者對五個 QA 資料集進行評估
在提問者已經知道答案的情況下,傳統的 IR 系統(比如 BM25)已足夠
在使用者真正尋求答案的資料集上,作者顯示出 learned retrival 的重要性,在 exact match 上比 BM25 好 19 個點
Introduction
由於閱讀理解系統的發展,人們對 open domain question answering (QA) 的興趣重新燃起
其中 evidence 得從 open corpus 取得,而不是直接從輸入給入
現有的方法需要 blackbox IR system 來完成大部分繁重的工作,即使它無法對下遊任務進行微調
在 DrQA 推廣的強監督環境中,他們也假設了一個訓練在 question-answer-evidence triple 上的閱讀理解模型
在某些人提出的 weakly supervised setting 中,他們假設 IR system 提供 noisy gold evidence
這些方法利用 IR system 來大幅減少搜尋空間
然而 QA 和 IR 有著根本性的差異
雖然 IR 關心的是 lexical 和 semantic matching,但 question 的定義並不具體,而且需要更多 language understanding,因為 user 在找的是未知資訊
我們應該直接 用 QA data 學習 retrieve,而不是受限於 blackbox IR system
在本文中,作者介紹了第一個 OpenRetrieval Question Answering system (ORQA) 框架
ORQA 學習從 open corpus retrieve evidence,並且只做 question-answer pair 的監督訓練
雖然最近的工作在改進 evidence retrieval 上取得了巨大的進展,但是他們依然只是在 closed evidence set 下 rerank
fully end-to-end 的挑戰是,open corpus 的 retrieval 必須被視為 latent variable,要 train from scratch 是不切實際的
IR system 提供了一個合理但可能非最好的起點
本文的一個關鍵是,如果用無監督 的 ICT 對 retriever 做預訓練,那 end-to-end learning 是有可能的
在 ICT 中,一個句子被視作 pseudo-question,而它的 context 被視作 pseudo-evdience
給定一個 pseudo-question,retriever 的目標是從 batch 中的 candidate 找出對應的 pseudo-evidence
ICT pretraining 提供了強大的初始化,使 ORQA 可以簡單地優化
作者在五個 QA 資料集上進行了評估,在問題作者已知答案的資料集上 (SQuAD、TriviaQA),檢索問題類似傳統的 IR,並且 BM25 是 SOTA retrieval
在問題作者不知道答案的資料集上 (Natural Questions、WebQuestions、CuratedTrec),作者顯示出 learned retrieval 的重要性,比 BM25 在 exact match 上好 6~19 個點
Overview
Task
在 open-domain QA 中,$q$ 是 question string,而 $a$ 是 answer string
與閱讀理解不同,evidence 的來源是 modeling choice,而非 task definition 的一部分
Formal Definitions
Model 把一個 unstructured text corpus 切成 B 塊的 evidence text
一個 answer derivation 是一個 pair $(b,s)$
$1 \le b \le B$ 是 block 的 index
$s$ 是 block $b$ 的 span
scoring function $S(b,s,q)$ 用來計算 $(b,s)$ 對於 $q$ 的分數
一般來說 scoring function 會被分解成 retrieval component $S_{retr}(b,q)$ 和 $S_{read}(b,s,q)$
- $S(b,s,q) = S_{retr}(b,q) + S_{read}(b,s,q)$
在推論階段:
- $a^* = TEXT(argmax_{b,s} S(b,s,q))$
open-domain QA 的一個主要挑戰是 handling the scale
作者在 English Wikipedia 上做實驗,包含超過 13M 個 blocks,每個 block 都有超過 2000 個可能的 spans
Existing Pipelined Models
在現有的 retrieval-based open-domain QA 模型中,blackbox IR system 先選擇一組 closed set of evidence candidates
然後 DrQA 之後的多數工作都用 TF-IDF 來挑選 candidate,並專注於閱讀理解或 reranking 的部分
reading component $S_{read}(b,s,q)$ 是從 gold answer 學習的
在最接近我們的方法的工作中,reader 是透過 weak supervision 學習的
retrieval system 會啟發式(heuristically)地刪除 spurious ambiguities,並把清理後的結果視為 gold evidence
Open-Retrieval Question Answering (ORQA)
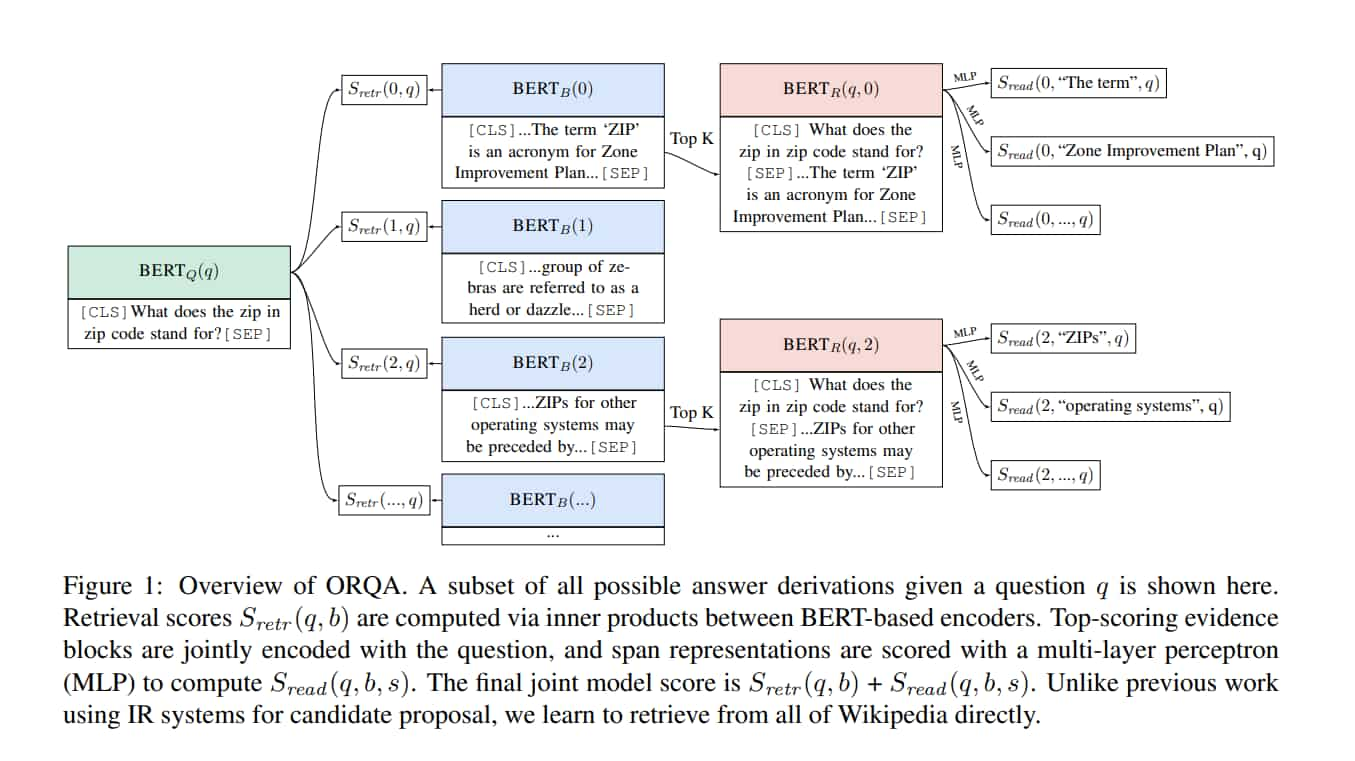
$BERT(x_1, [x_2]) = \{CLS: h_{CLS}, 1: h_1, 2: h_2,…\}$
Retriever component
- $h_q = W_q BERT(q)[CLS]$
- $h_b = W_b BERT(b)[CLS]$
- $S_{retr}(b,q) = h_q^T h_b$
Reader component
- $h_{start} = BERT_R(q,b)[START(s)]$
- $h_{end} = BERT_R(q,b)[END(s)]$
- $S_{read}(b,s,q) = MLP([h_{start};h_{end}])$
Inference & Learning Challenges
上面的模型概念很簡單
但推論和學習上具有挑戰性,因為:
- open evidence corpus 有巨大的搜尋空間(超過 13M 個 blocks)
- 要如何在空間 navigate 是 latent
因此標準的 teacher forcing 不能用,latent variable 也不能用,因為存在大量 spuriously ambiguous derivations(比如答案是 “seven”,很多 evidence 都會有 “seven” 這個字眼)
作者透過非監督預訓練來良好地初始化 retriever 來解決這些挑戰
預訓練的 retriever 使作者能夠:
-
pre-encode Wikipedia blocks,從而在 finetune 階段實現動態且快速的 top-k retrieval
-
使 retrieval 可以遠離 spuriously ambiguities 並偏向 supportive evidence
Inverse Cloze Task
作者提出的預訓練流程的目標是想讓 retriever 解決和 evidence retrieval for QA 相似的無監督任務
直覺上,useful evidence 通常會討論問題中的 entities, events 和 relations
還包含問題中不存在的額外資訊 (the answer)
question-evidence pair 是 setence-context pair,句子的上下文在語意上是相關的,可以推論句子中缺少的資訊
憑這種想法,作者建議使用 ICT 來預訓練 retriever
在 standard cloze task 中,目標是根據上下文預測 masked-out text
相反,ICT 要逆向預測,給定一個句子,預測上下文
使用類似 downstream retrieval 的 discriminative objective:
$P_{ICT}(b|q)=\frac{exp(S_{retr}(b,q))}{\sum_{b’ \in BATCH} exp(S_{retr}(b’,q))}$
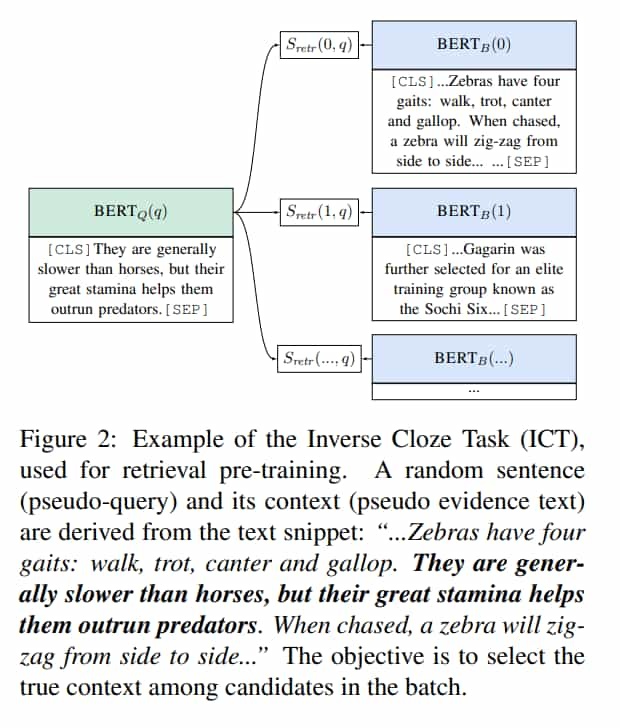
預測哪個上下文是 query 的
ICT 有個重點是,它要做的不僅僅是單字匹配,因為 evidence 中沒有 pseudo-question
例如 fig.2 的 pseudo-question 完全沒有提及 zebra,但 retriever 要能夠選擇 zebra 的 context
能夠從非指定的語言推論出語意是 QA 和傳統 IR 的差異
然而作者也不想阻止 retriever 學習單字匹配,因為 lexical overlap 最終是一個非常有用的特徵
因此,作者只在 90 % 的例子中把 sentence 從 context 中移除,鼓勵模型在需要的時候學習抽象表示,也在可用時學習 low-level word matching features
ICT 預訓練實現兩個主要目標:
-
儘管預訓練的句子和微調時的 question 不匹配,但作者預期 zero-shot evidence retrieval performance 足以引導 latent variable 的學習
-
pretrained evidence blocks 和 downstream evidence blocks 間沒有這種不匹配的問題
因此可預期 $BERT_{B}(b)$ 無須進一步訓練即可正常工作
只有 question encoder 需要針對下遊資料微調
Inference
由於 fixed block encoder 已經為 retrieval 提供了有用的 representation,可以預先計算所有 block 的 encoding
因此在微調的時候不需要對大量 evidence block 重新 encode,並且可以使用比如 locality-sensitive hashing 之類的現有工具來建立索引
透過 pre-compiled index,推理遵循 standard beam-search
檢索 top-k evidence block,並只計算這 k 個 block 的 reader score
Learning
這邊太複雜,建議看原文
Experimental Setup
Open Domain QA Datasets
對 5 個現有 question answering 或閱讀理解資料集進行評估
並非所有資料集的原始形式都是 open-domain QA,因此作者遵循 DrQA 的做法,轉成 open format
每個 example 都有一個 single question 和一「組」 reference answer
Natural Questions
包含了從 Google Search 的 aggregated queries 中的 question
為了蒐集這個資料集的 open version,作者只保留 short answer 並丟棄 evidence document
具有許多 token 的答案通常類似 extractive snippets 而不是 canonical answer,因此作者丟棄長度超過 5 個 token 的答案
WebQuestions
包含從 Google Suggest API 抽取的問題
答案是根據 Freebase 標註的,但是只保留 entities 的 string representation
CuratedTrec
問題來自真實查詢的各種來源,比如 MSNSearch
TriviaQA
從網路上抓的 question-answer pairs
作者使用 unfiltered set 並捨棄 distanly supervised evidence
SQuAD
被設計來用作閱讀理解,而不是 open-domain QA
答案範圍是從 Wikipedia 的段落中選擇的,問題由 annotators 編寫,annotators 被指示提出問題,要由給定的 context 中的 span 來回答
Dataset Biases
在 Natural Questions、WebQuestions 和 CuratedTrec 中,提問者不知道答案,反映了真實的尋求問題的分佈
但是,annotators 必須單獨找到正確的答案,因此需要 automatic tools,並可能會對這些工具的結果產生 bias
在 TriviaQA 和 SQuAD 中,不需要 automatic tools,因為 annotators 是根據已知答案寫問題的
然而這引入了另一組可能更成問題的 bias,就是撰寫問題並非出於資訊需求
導致問題中有許多自然出現的問題中沒有的提示
這在 SQuAD 中問題特別嚴重,使問題和 evidence 間人為地出現大量詞彙重疊
但上述這些只是想表達資料集的屬性,而非可採取行動的批評,因為要取得大規模資料必定會遇到這些狀況,目前還不清楚如何在合理的成本下收集公正的資料集
Implementation Details
Evidence Corpus
corpus 被分成最多 288 個單字的 chunk,並且保留 sentence boundaries
導致有超過 13M 個 blocks
Main Results
Baselines
BM25
BM25 是事實上的非監督搜索方法 SOTA 被證明對於傳統資訊檢索任務和 QA 的 evidence retrieval 任務都是 robust
Language Models
非監督的 neural retrieval 對於傳統 IR 來說很難改進,但這裡視作比較的 baseline
作者對 LM 進行實驗,並且這已被證明是 SOTA unsupervised representation
我們與兩種廣泛使用的 128-dimensional representation 進行比較:
- NNLM
- context-independent embedding
- ELMO
- context-dependent bidirectional LSTM
就像 ICT 一樣,使用 alternate encoder 來預先計算 encoded evidence blocks 還有初始化經過 finetune 的 question encoding
根據現有的 IR 文獻,還有 LM 沒有顯著優化 retrieval 的直覺,作者並不期望這些成為強大的 baseline,但是他們證明了將文本編碼為 128 維的難度
Results
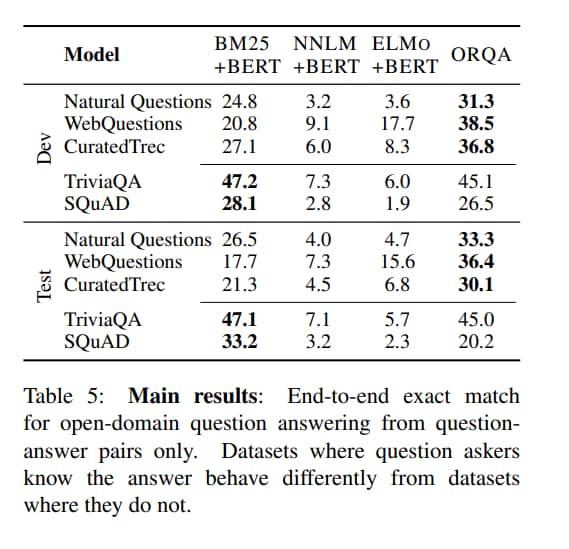
在提問者已經知道答案的資料集中
證實壓縮到 128維的向量無法與 BM25 精確表示 evidence 中每個單字的能力相符
SQuAD 的 dev 和 test 間的顯著下降反映了資料集中的某個特性 - 10 萬個問題僅源自 536 個文件
因此,SQuAD 的好的檢索目標,會和訓練範例高度相關,違反了 IID 假設,使其不適合學習檢索
因此,作者強烈建議對 end-to-end open-domain QA models 有興趣的人不再使用 SQuAD 進行訓練和評估
Analysis
Strongly supervised comparison
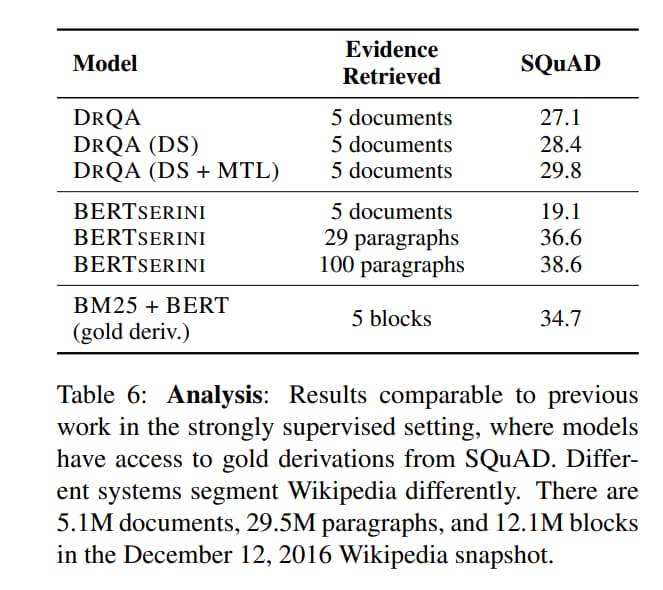
為了證實作者的 BM25 Baseline 是 SOTA,提供了和 DrQA 的比較
DrQA 的 reader 是 DocReader,用 TF-IDF 取得 top k documents
還包括基於 TF-IDF retrieval 的 distant supervision
BERTserini 的 reader 是一個基於 base BERT(類似作者的 reader),並用 BM25 搜索 top-k 個段落(像作者的 BM25 baseline)
主要區別在 BERTserini 使用 Wikipedia 中的真實段落,而不是任意 block,從而由於長度不均導致更多 evidence blocks
為了和這些強監督系統進行比較,作者在 SQuAD 上預訓練 reader
Masking Rate in the Inverse Cloze Task
pseudo-query 在 90% 的時間裡都從 evidence block 遮蔽
如果總是屏蔽 pseudo-query,那麼 retriever 永遠不會知道 n-gram overlap 是一個強大的 retrieval signal,導致損失 10 個點
如果從不屏蔽,問題就會簡化為記憶,導致不能很好地推廣到問題
Example Predictions
發現 ORQA 在具有高度詞彙重疊的文本更加 robust
但是由於 128 維向量的資訊有限
很難精確地表示極為具體的概念,比如準確日期