paper: Matryoshka Representation Learning
Abstract
想設計 flexible 的 representation 好適應不同的下游任務
MRL 根據不同的 granularities 來 encode 資訊,並允許一個 single embedding 來適應下游任務的運算限制
MRL 學習從 coarse-to-fine 的 representation,至少和獨立訓練低維度的 representation 有一樣的準確度
在相同精準度下,MRL 的 embedding 縮小 14 倍
在 ImageNet-1K 和 4K 上進行大規模檢索時,實際速度提升 14 倍
long-tail few-shot learning 的準確度提高 2%,並且和原有 representation 一樣 robust
最後,作者證明 MRL 可以無縫地擴展到各種模式的網路規模資料集,包含 Vision, Vision + Language, 和 Language
Introduction
deep representation 的 deployment 有兩個步驟:
- 昂貴的 forward-pass 計算 representation
- representations 在下游的利用 (比如檢索)
在 web-scale 上,這種利用的成本蓋過了特徵計算成本
常見的做法的 representation 的剛性迫使多個任務中使用高維嵌入向量
人類對自然世界的感知是由粗到細的粒度
然而,或許是基於梯度訓練的 inductive-bias,深度學習傾向於將「資訊」擴散到整個表示向量中
通常透過訓練多個低維模型、聯合優化不同容量的子網路、事後壓縮,在現有的 fixed representation 上實現彈性
這些技術中的每一種都難以滿足自適應大規模部屬的要求,基於開銷 / 維護考量等等
MRL 以 nested 的方式來學習 O(log(d)) 個相同的高維向量、但不同 capacity 的 representation,因此被稱為 Matryoshka
Matryoshka Representation 提高了大規模分類和檢索的效率,而不會顯著失去準確度
本文重點關注在機器學習系統的兩個關鍵模組:大規模分類和檢索
在分類上,作者使用 variable-size representations 結合 adaptive cascades 來顯著減少實現特定精度所需嵌入的平均維度
例如,在 ImageNet-1K 上,MRL + Adaptive classification 在和 baseline 同精準度的情況下將 representation 縮小 14 倍
對於檢索,先用 query embedding 一開始的 few dimensions 來減少 retrieval candidates,然後再用更多的 dimensions 來 re-rank retrieved set
MRL 的檢索精確度和 single-shot retrieval 相當
主要貢獻如下:
- 提出了 MRL 來獲得 filexible 的 representation for adaptive deployment
- 使用 MRL 進行大規模分類和檢索,速度提高 14 倍而且一樣準確
- 可以在跨 modalities 還有可接受 web-scale 資料的情況下無縫調整 MRL
- 在其他下游任務的背景下進一步分析 MRL 的表示
Related Work
Efficient Classification and Retrieval
在推理過程中,分類和檢索的效率可以從兩個方面研究:
- 深度特徵的高但恆定的成本
- 隨著標籤空間和數據大小而變化的搜索成本
第一個問題可以透過不同的演算法設計高效的神經網路來解決
但是,伴隨著強大的 featurizer,多數 scale 相關的問題出在 標籤數量(L)、資料大小(N)、或是表示維度(d) 這種 linear dependence 上
讓 RAM, disk 和 CPU 都同時有巨大的壓力
標籤數量在計算和 RAM 方面已經得到了很好的研究,可以透過 Approximate Nearest Neighbor Search (ANNS) 或 leveraging the underlying hierarchy 來解決
在表示大小方面,降維、Hash 和特徵選擇等技術常用於緩解 O(d) 的增長規模,但代價是精確度的顯著降低
ANNS 使用戶可以從資料庫中取得和請求最相似的文件或圖片
廣泛採用的 HNSW 可以讓 O(d log(N)) 和準確搜索 O(dN) 一樣精準,但代價是需要在 RAM 和 disk 承擔 graph-based index 的開銷
MRL 解決對 d 的線性依賴問題,低維度的 Mayryoshka representations 和獨立訓練的 representations 一樣準確,而不需要多次昂貴的前向傳遞
Matryoshka Representation Learning
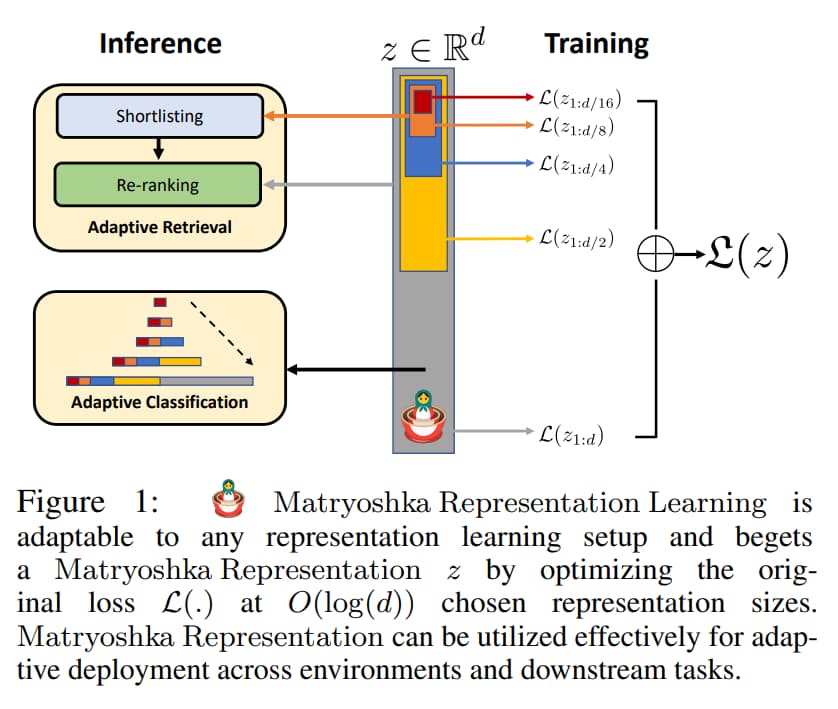
有分兩種訓練方法:
-
Matryoshka Representation Learning (MRL)
- 在後面接 9 層 MLP,不是串聯,是並聯
- 比如 mlp(768,8)…., mlp(768,2048)
-
Efficient Matryoshka Representation Learning (MRL-E)
- 在後面只接 1 層,然後取前面維度得到一個向量,以此類推
- 比如 mlp(768, 2048),可能取前 16 維當一個向量,然後再取前 64 維當一個向量