paper: PonderNet: Learning to Ponder
Abstract
CNN 在 CV 領域是首選,但基於 attention 的網路也在變流行。
本文證明雖然 convolution 和 attention 都可以獲得良好的 performance,但皆非必須。
本文提出了 MLP-Mixer,一種純 MLP 的架構,包含兩種 layer:
- 將 MLP 獨立用在 patch
- mixing per-location features
- 將 MLP 用在 patches 之間。
- mixing spatial information
Introduction
本文提出了完全基於 MLP 的 MLP-Mixer ( 又簡稱 Mixer ),有競爭力卻概念和技術上都很簡單。
有兩種 MLP layer:
-
Channel-Mixing MLP
- 用在每個 patch 上
- 讓不同 channel 之間的資訊互相交換
-
Token-Mixing MLP
- 用在所有 patch 上
- 讓空間資訊互相交換
這兩者交錯出現,讓兩個輸入維度可以交互作用
在極端情況下,本文的架構可以看做是一個非常特殊的 CNN,使用 1*1 卷積做 channel mixing,並用 single-channel 且 full receptive field 的 1D 卷積做 token mixing。
反之則不然,因為經典的 CNN 並不是 Mixer 的特例。
盡管很簡單,但 Mixer 卻取得有競爭力的結果。
然而與 ViT 一樣,在一切特有的 CNN 架構下略有欠缺。
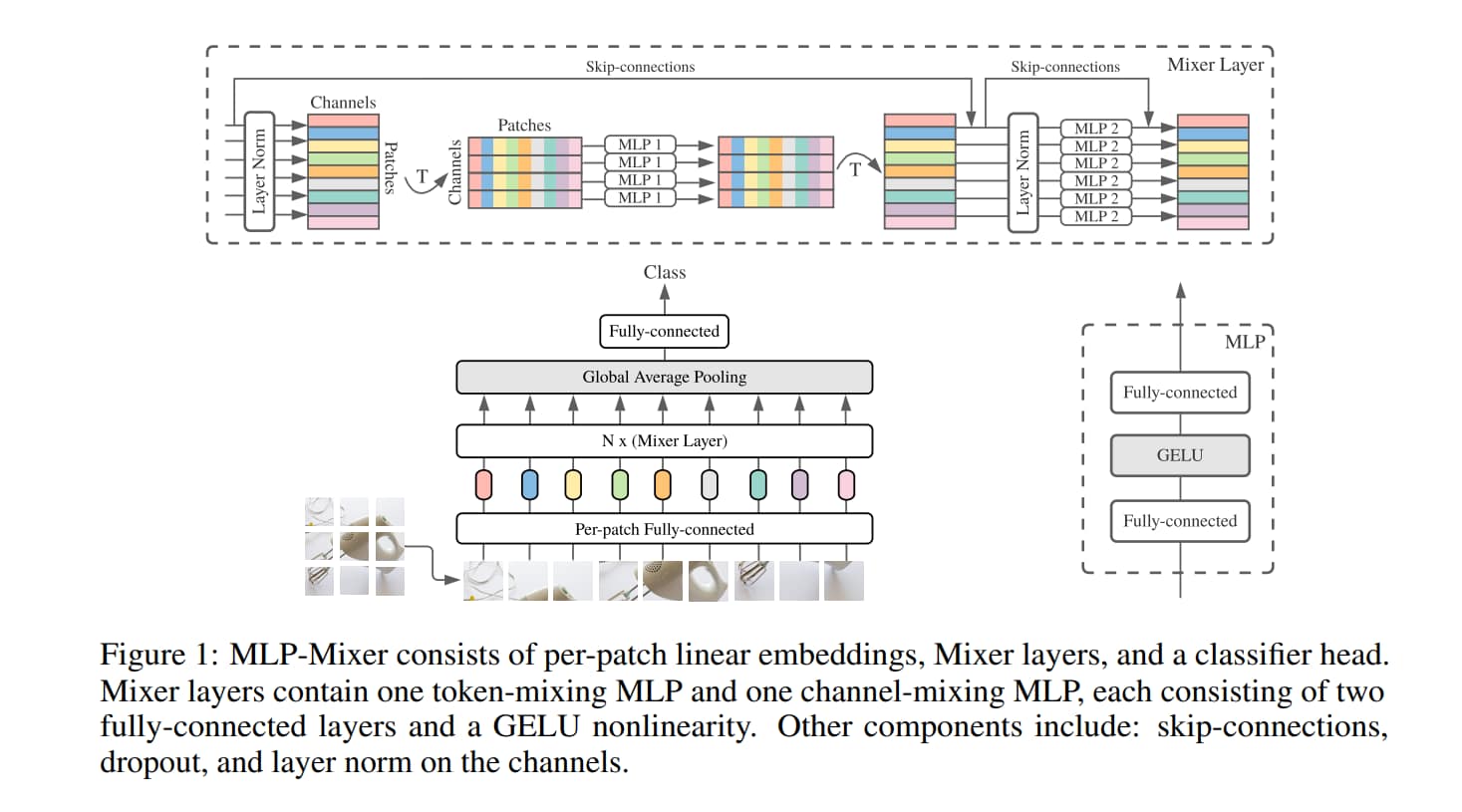
Mixer Architecture
Mixer 的核心概念是想把
- mix features at a given spatial location
- mix features between different spatial locations
給分開來
所有的 patch 都是用同一個 projection matrix
注意 fig1 的 MLP2,他們共享同樣的參數,這樣綁定參數可以預防 C 和 S 增加時使架構增長過快。在 seperable convolution 中,不同通道使用不同的 kernel。不過作者這樣的選擇並不影響實際的 performance。
Mixer 的所有 Layer 都具備相同的輸入大小。
這種「isotropic」的設計和 Transformer 或 RNN 比較像。
與大多數具有 pyramidal structure 的 CNN 不同,它們在更深的層有更低的 resolution,但有更多 channel。
不過上面只是探討典型的設計,也存在例外,比如 isotropic Resnet 或 pyramidal ViT。
除了 MLP,Mixer 還有用到 LayerNorm 和 skip connection。
但是 Mixer 沒有用到 positional encoding,因為 token-mixing MLP 本身就對位置敏感。\
Experiments
Mixer 用中大型資料集預訓練,然後在一系列中小資料集上評估。
目標不是拿到 SOTA,而是顯示出與 SOTA 的 CNN 和 attention-based model 相比,Mixer 有競爭力。
Fine-tuning
在 fine-tuning 時,用比預訓練時還要高的 resolution。 由於每個 patch 的 resolution 是固定的,這樣會導致有更多的 patches。
對於這個問題,採用以下解法:
我們原先預計吃 S 個 patch,現在我們由於輸入解析度更高,而且 patch 大小不變,所以我們得到一個比 S 還大的 $S’$。 所以我們在很多地方就需要比原先權重矩陣 W 還更大的 $W'$
我們要把 $S’$ 拆成 $K^2$ 個長度為 $S$ 的 sequence,K 是整數。
並且我們把 $W’$ 的 shape 改成 $(W.shape[0] * K^2, W.shape[1] * K^2)$
然後我們把 $W’$ 作為 block-diagonal matrix 來初始化,把 $W$ copy 好幾份,放在 main diagonal 上。
所有權重都用類似的處理方法。