paper: Training language models to follow instructions with human feedback
Abstract
把語言模型變大不代表他們會更好地遵循用戶的意圖。
大的語言模型有可能會生成 untruthful, toxic, not helpful 的答案。
該論文透過 fine-tuning with human feedback 來解決這問題。
一開始準備一系列人工標註的 prompts,然後用這 dataset 對 GPT-3 做 fine-tune。
接下來再蒐集一個 dataset,存放 rankings of model outputs,由人工判斷輸出好壞,再用 RL 把剛剛 fine-tune 過的 model 繼續 fine-tune。
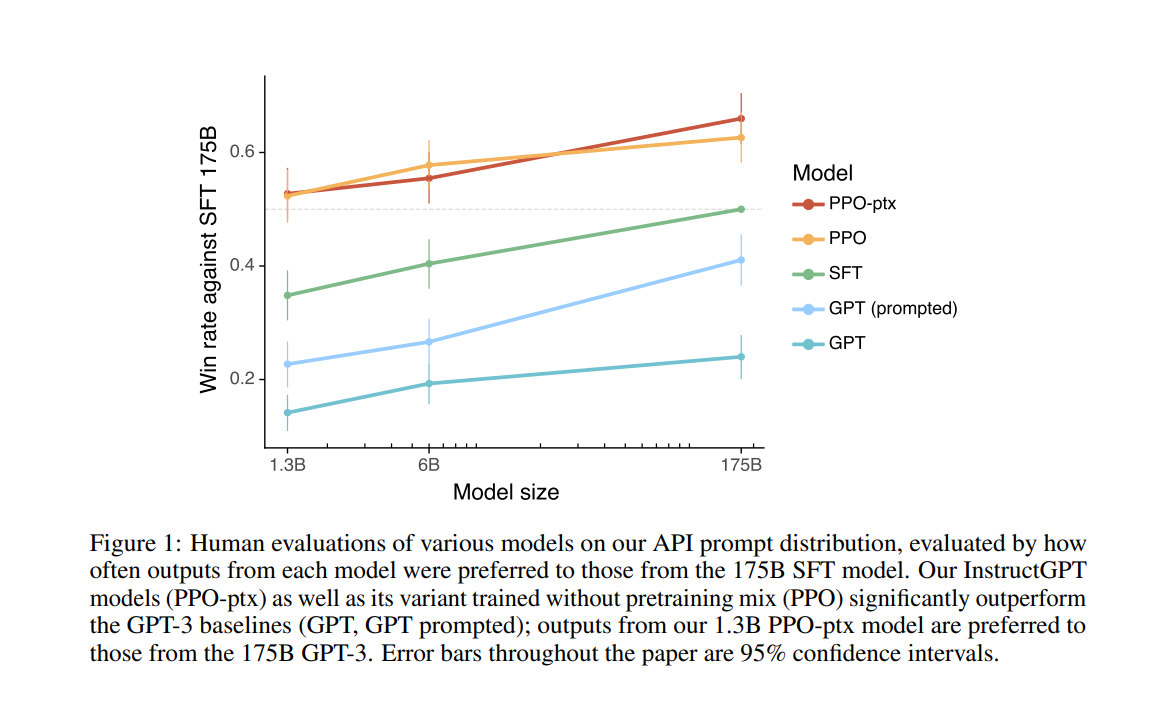
最後有 1.3B 參數的 InstructGPT 表現的結果比 175B 參數的 GPT-3 還好。
Introduction
Large language models(LMs) 可以透過 “prompt” 來執行各種 NLP 任務。
但這些模型也常有一些非目的性的行為,諸如捏造事實等等。
原因是出在目標函數上,多數 LMs 的目標函數是根據網路上的文本生出下一個字詞。
這和「根據使用者指令生出安全且有幫助的答案不同」。
上述的差異使語言模型的目標是 misaligned。
作者的目標是生出 helpful、 honest(沒有誤導性資訊)、harmless 的 model。
具體作法,使用 reinforcement learning from human feedback(RLHF)。
訓練步驟
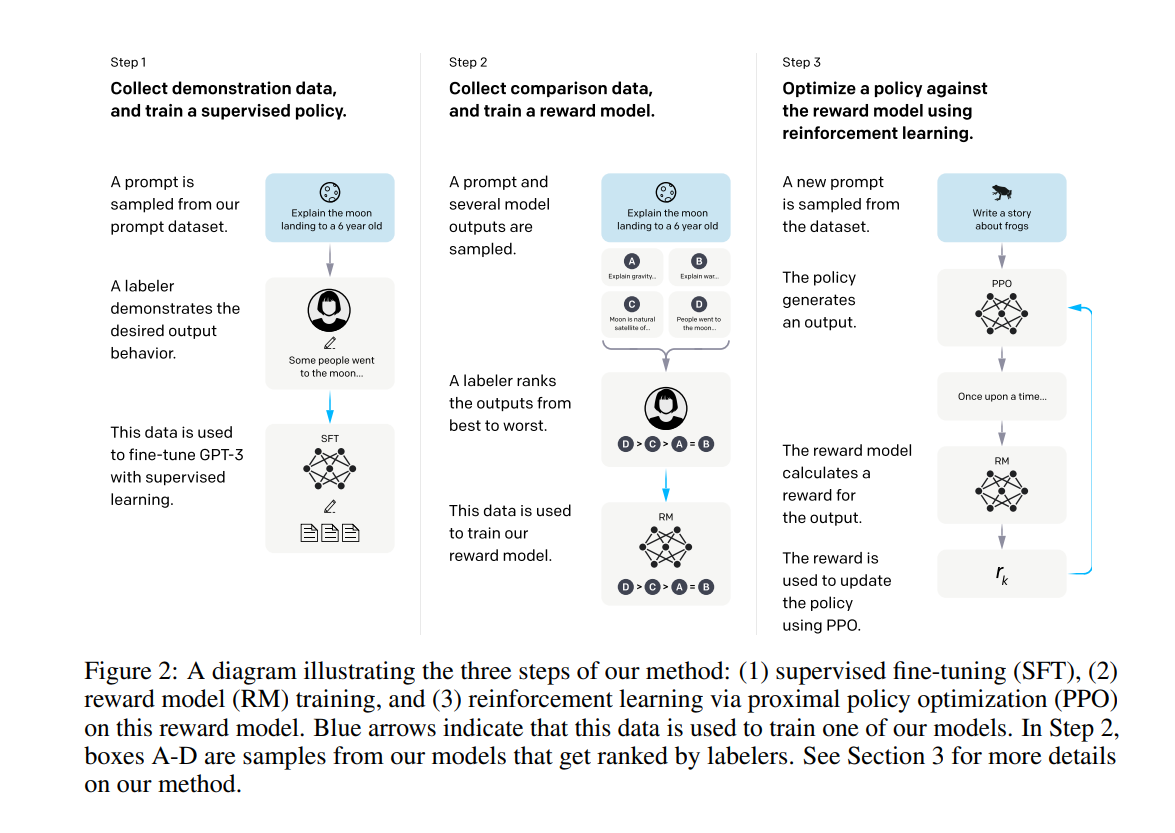
結果
-
Labelers 明顯偏好 InstructGPT 的答案,勝過 GPT-3 的答案
-
InstructGPT 的答案在 truthfulness 勝過 GPT-3 的答案
-
InstructGPT 的答案在 toxicity 上小勝 GPT-3 的答案,但在 bias 上沒有
Methods
Dataset
標註人員寫很多 prompts
- Plain:
- 隨便寫任意任務
- Few-shot:
- 想個 instruction,並寫 multiple query/response pairs for that instruction
- User-based:
- 根據一些申請使用 OpenAI API 的用戶,提出有關的 prompts
然後根據這個訓練初步模型,並把這個初步模型放到他們的 Playground 給用戶使用。
再把用戶問的問題蒐集回來,並做篩選。
訓練 SFT 的模型用 13k training prompts
訓練 RM 的模型用 33k training prompts
訓練 PPO 的模型用 31k training prompts
Model
-
Supervised fine-tuning(SFT)
- 拿 GPT-3 去訓練 16 個 epochs
- 跑一個 epoch 就發現 overfitting,但發現訓練更多 epoches 對後面的 RM 有用,而且這個 model 也只是過渡產品
-
Reward modeling(RM)
-
把 SFT 後面的 unembedding layer 去除掉,接上線性層,最後輸出一個 scalar reward
-
用 6B RMs
-
這模型會吃 prompt 和 response
-
人工標記的是排序,不是分數
-
對每個 prompt 生出 9 個答案
- 原本是 4 個,但排 9 個花的時間可能不會到 4 個的兩倍,因為主要心力會花在讀 prompt。但標註訊息會多很多,因為都是兩兩比較。
- 而且在 loss 中最多只要丟入 RM 9 次,因為可以重用
-
Pairwise Ranking Loss
- 對一個 prompt(假設是 x),取出一對回覆(假設是 $y_w$ 和 $y_l$),算出 RM(x, $y_w$) 和 RM(x, $y_l$),假設 $y_w$ 比 $y_l$ 排序高,讓 RM(x, $y_w$) - RM(x, $y_l$) 的數值越大越好
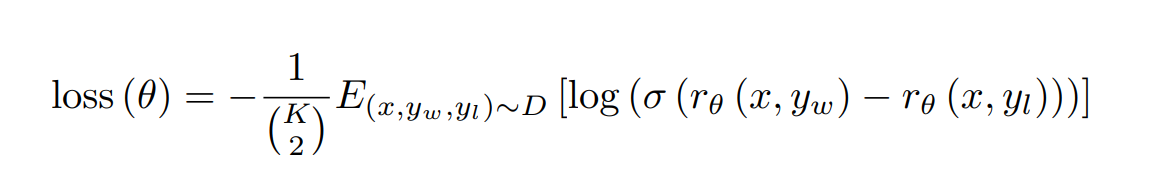
-
-
Reinforcement learning(RL)
-
PPO
-
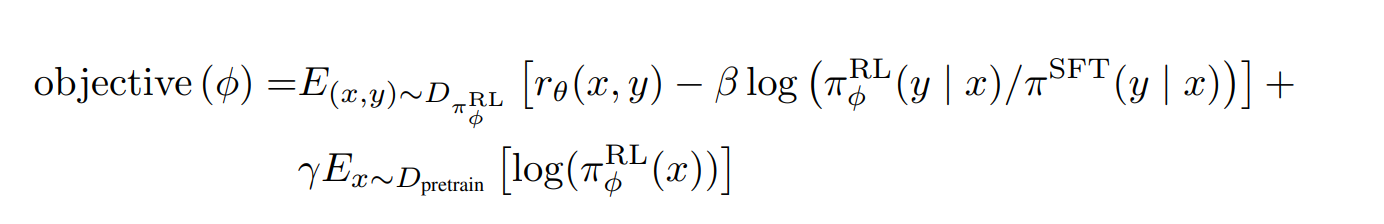
- $\beta$ 那項是 KL divergence
- $\gamma$ 那項是不想要讓這 model 太專注在微調的任務,而失去原本在其他 NLP 任務也表現很好的功能。
- $D_{pretrain}$ 是 pretraining distribution
- 如果 $\gamma$ 為 0,在該實驗中叫做 PPO,否則,稱為 PPO-ptx
-
Result