paper: Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset
Abstract
目前的動作分類資料集 (UCF-101 和 HMDB-51) 的影片非常缺乏,使辨識「良好的影像架構」變得困難, 使多數方法在現有的小規模 benchmark 的表現差不多。為此本文根據新的 Kinetics Human Action Video dataset 對 SOTA 架構進行了重新評估。
Kinetics 有 400 個人類動作類別。每個類別有 400 個 clip。從 YouTube 上獲取的,而且每個 clip 來自 unique 的 youtube 影片。
本文分析了當前架構在 Kinetics 上動作分類任務的表現,也評估 Kinetcis 用作預訓練的效果。
本文提出了一種基於 2D ConvNet inflation 的 Two-Stream Inflated 3D ConvNet (I3D)。
I3D 的擴展方法讓 ImageNet 上已經取得成功的架構可以被利用在解決影像任務上。
結果表明,經過在 Kinetics 上預訓練後,I3D 在動作分類方面顯著提高了 SOTA,在 HMDB-51 上達到 80.9%,在 UCF-101 上達到 98.0%。
Introduction
在 ImageNet 上預訓練模型的效果很好,但在影片領域,預訓練成效一直是一個未知的問題。因為流行的動作識別 benchmark 都非常小,約略只有 10k 個影片。
Kinetics 有 400 個人類動作類別。每個類別有 400 個 clip,而且每個 clip 都來自一個 unique 的 Youtube 影片。
本文實驗策略是在 Kinetics 上預訓練,再在 HMDB-51 和 USC-101 上微調,結果顯示出預訓練總是能提高性能,但提升多寡因架構而異。
本文提出新架構,稱為「Two-Stream Inflated 3D ConvNets」(I3D),建立在 SOTA 的影像分類架構上,並將 filters 和 pooling kernel 膨脹成 3D。
基於 Inceptionv1 的 I3D 在 Knetics 上預訓練後,性能遠超過當前的 SOTA 架構。
在本文的模型中,並沒有考慮更多經典方法,比如 bag-of-visual-words representation,但 Kinetics 是公開的,因此其他人可以進行後續研究。
Action Classification Architectures
目前影片架構中的一些主要區別如下:
- 卷積是 2D 還 3D 的
- 是否只是 RGB 影片,還是包含事先計算的 optical flow
- 對於 2D ConvNets,訊息是怎麼在 frame 之間傳遞的
- 這部分可以使用 temporally-recurrent layers,比如 LSTM,或是用隨時間的 feature aggregation 來完成。
在本文中,考慮了涵蓋大部分現有架構的模型子集:
- 2D ConvNets
- 頂部有 LSTM 的 ConvNet
- 有兩種 stream fusion 的 two-stream networks
- 3D ConvNets
- C3D
由於參數維度較高,以及缺乏 labeled video data,以前的 3D ConvNet 相對較淺(最多 8 層)。
本文發現諸如 VGG-16 和 ResNet 等很深的影像分類網路可以輕鬆擴展成 spatio-temporal feature extractors,並且他們的預訓練權重也可以提供有價值的初始化。
本文也發現 two-stream 的作法依然有用。
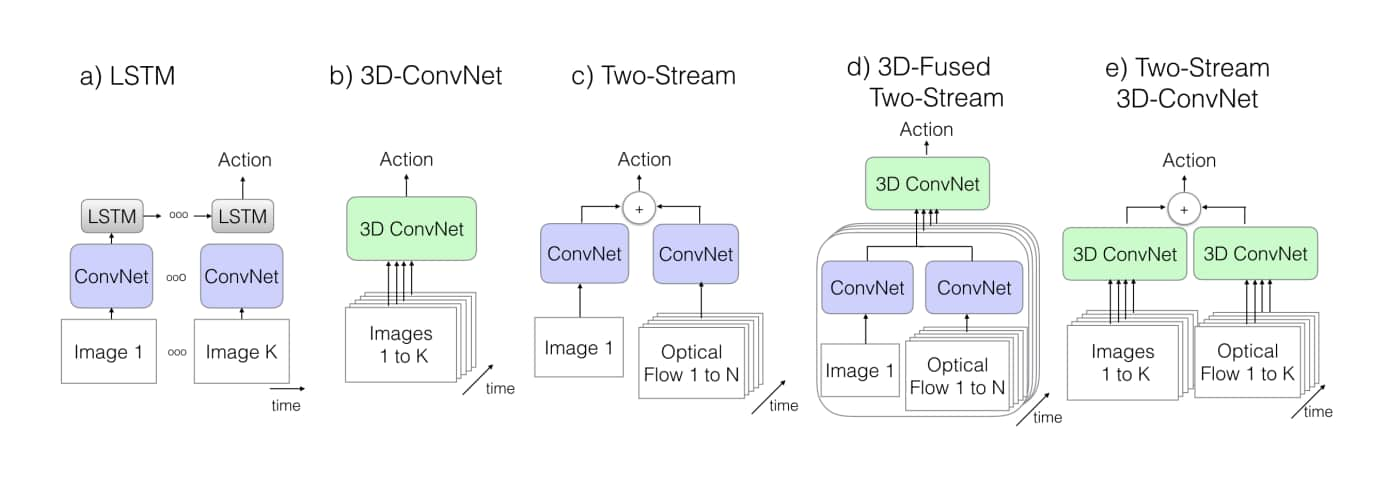 fig2. K 是影片中的 frame 的總數,N 是相鄰 frames 的子集合。
fig2. K 是影片中的 frame 的總數,N 是相鄰 frames 的子集合。
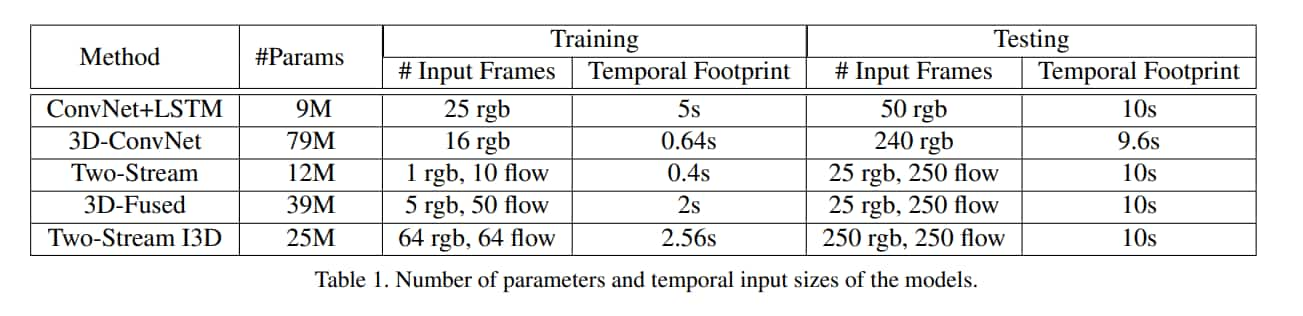
上圖是本文實驗的五種架構,前四種是之前的做法,最後一種是提出的新作法。 上圖中除了 C3D 外都有用到 ImageNet 預訓練的模型。
時間是根據 input 的 frame 換算出來的,fps 是 25,除了 LSTM 那個比較特別,因為 LSTM 那個是每 5 frame 取 1 frame,所以時間是 5 倍。
之前的做法
-
ConvNet+LSTM
有一種做法是把每個 frame 獨立餵給 2D Conv,然後再把預測做彙整,符合 bag of words image modeling 的精神,但這樣會忽略時間結構上的資訊,比如無法判斷開門或關門。
所以最好在後面加一個 recurrent layer,所以這邊就用 Inception-V1 結合 LSTM。
原始的影片 stream 是 25 fps,這邊每 5 frame 採樣一次。
-
3D ConvNets
和一般的卷積神經網路差不多,只是具有 spatio-temporal filters。
但由於額外的 kernel 維度,相比 2D Conv 會有更多參數,也使他們更難訓練。
而且這樣會無法發揮 ImageNet 預訓練的好處,因此之前的工作都定義了相對淺層的架構,並且從頭訓練。
benchmark 中的表現備受期待,但和 SOTA 比沒有競爭力,也因此成為本文實驗的良好候選者。
本文用的是 C3D 的小變體,差異在於所有卷積層和 FC 層的後面都用了 BN。 而且在第一個 pooling layer 用的 stride 是 2,好減少記憶體的使用,比用更大的 batch,這在 BN 中非常重要。
-
Two-Stream Networks
Roy:這裡由於比較複雜,我要改提 two-stream 的原始論文(Two-Stream Convolutional Networks for Action Recognition in Videos)說明這東西是什麼
簡而言之就是分成兩個部分:
-
空間資訊:
用影片的一個 frame 經過卷積神經網路達成,這個 frame 用來提取影像中的物件資訊,比如打排球這動作可能辨識出排球就非常好判定,所以用某個 frame 來提取空間資訊。
-
動作資訊:
這邊用一連串的光流(optical flow)圖來達成,光流是物體(pixel)在兩個 frame 間的位移向量,估計方法有很多,這裡不一一舉例。

上圖出自 Two-Stream Convolutional Networks for Action Recognition in Videos,圖 c 就是光流,具有兩個方向,指出像素的位移,圖 d 是水平方向的視覺化,圖 e 是垂直方向的視覺化。
再把這些光流圖餵給卷積神經網路,用作動作資訊的判別。
值得一提的是他是 late fusion,而且是用加權平均,不是像一般想的把特徵結合再做其他處理。
-
The New: Two-Stream Inflated 3D ConvNets
作者把成功的 2D 分類模型簡單地轉換為 3D
Inflating
做法是把方形的 filter 改成立方體,把 N x N 的 filter 改成 N x N x N 的 filter,但這只有架構上的參考。
Bootstraping
把權重也給轉換到 3D 架構的方法。
作者觀察到影像可以透過反覆複製貼上來生出一個「不會動的無聊影片」, 透過這些影片,3D 模型可以透過這種方式在 ImageNet 上 implicitly pretrain,做法就是讓 3D filter 吃無聊影片的輸出和 2D filter 吃單一 frame 的輸出相同,做法如下:
我們可以沿時間維度重複 2D filter N 次,把這權重給 3D filter,同時把權重除以 N,達到這種效果。
Pacing receptive field growth in space, time and network depth
以往在圖片上對水平和垂直軸的對待是平等的,pooling kernel 和 stride 都一樣。 使感受野在兩個維度上隨著模型越來越深,慢慢平等增長。
但是時間軸用對稱的感受野不一定最好,而該取決於 frame rate 和 image dimensinos。 如果時間相對於空間增長太快,可能會混淆不同對象的邊緣,影響早期的特徵檢測。如果增長太慢,可能無法很好地捕捉場景動態。
實驗中,輸入影片的 fps 是 25。
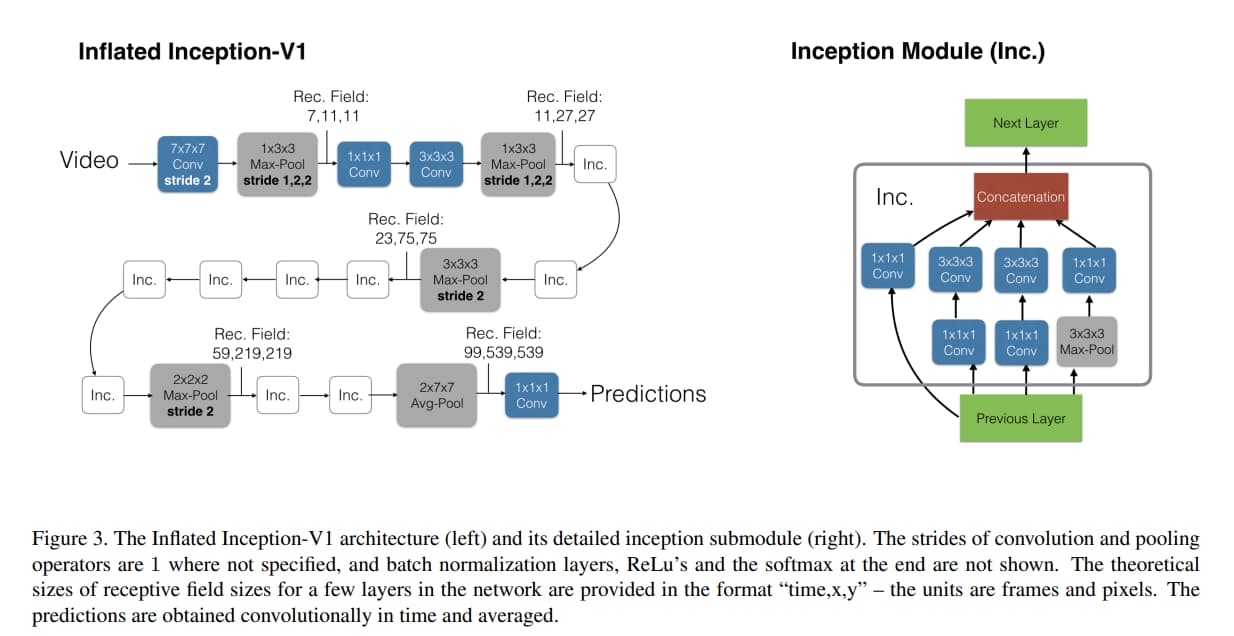
作者發現在前兩個 max pooling layer 不在時間軸 pooling(透過用 1 x 3 x 3 的 kernel,並且時間軸的 stride 是 1),並在其他 max pooling layer 都用 symmetric kernels 和 stride 是有幫助的。
最後的 average pooling layer 是用 2 x 7 x 7 的 kernel。
作者用 64 frame 訓練,但用整個影片測試。(averaging predictions temporally)
我想了一下,250 / 64 除不進,但是我看 code 發現他好像寬高 224 * 224 的照片會在最後經過 Average pool 後變成 1 * 1,所以他可以直接用 1 * 1 * 1 的卷積核把輸入通道改成分類數,再把時間軸的結果平均。
Two 3D Streams
分別訓練兩個網路,並在測試階段對預測進行平均。
這邊作者說光流的演算法某種意義上是 recurrent(例如,對於 flow fields 進行 iterative optimization),我不太懂這邊是什麼意思,我想作者用的光流演算法應該是透過某種類似 EM 演算法那種不斷迭代去逼近數值的演算法,但作者提到「或許是因為缺乏 recurrence,我們發現雙流有價值」,我不太懂為什麼需要 recurrence 效果才會好。
但結論是 two-stream 依然具備價值。
Implementation Details
這邊講滿詳細的,有興趣可以去原文看。 只提一下幾點:
- 光流演算法是用 TV-L1。
- 除了類似 C3D 的 3D ConvNet 都用使用 ImageNet 預訓練的 Inception-V1 作為 base network。
- 對於較短的影片,會重複循環以滿足模型的輸入介面
- 測試時會在中間剪裁 224 x 224
The Kinetics Human Action Video Dataset
Kinetics 有 400 個人類動作類別。每個類別有 400 個 clip,而且每個 clip 都來自一個 unique 的 Youtube 影片,共有 24 萬個訓練影片。
每個 clip 都大約 10 秒,而且沒有未剪的影片。
測試集每個 class 包含 100 個 clip。
Experimental Comparison of Architectures
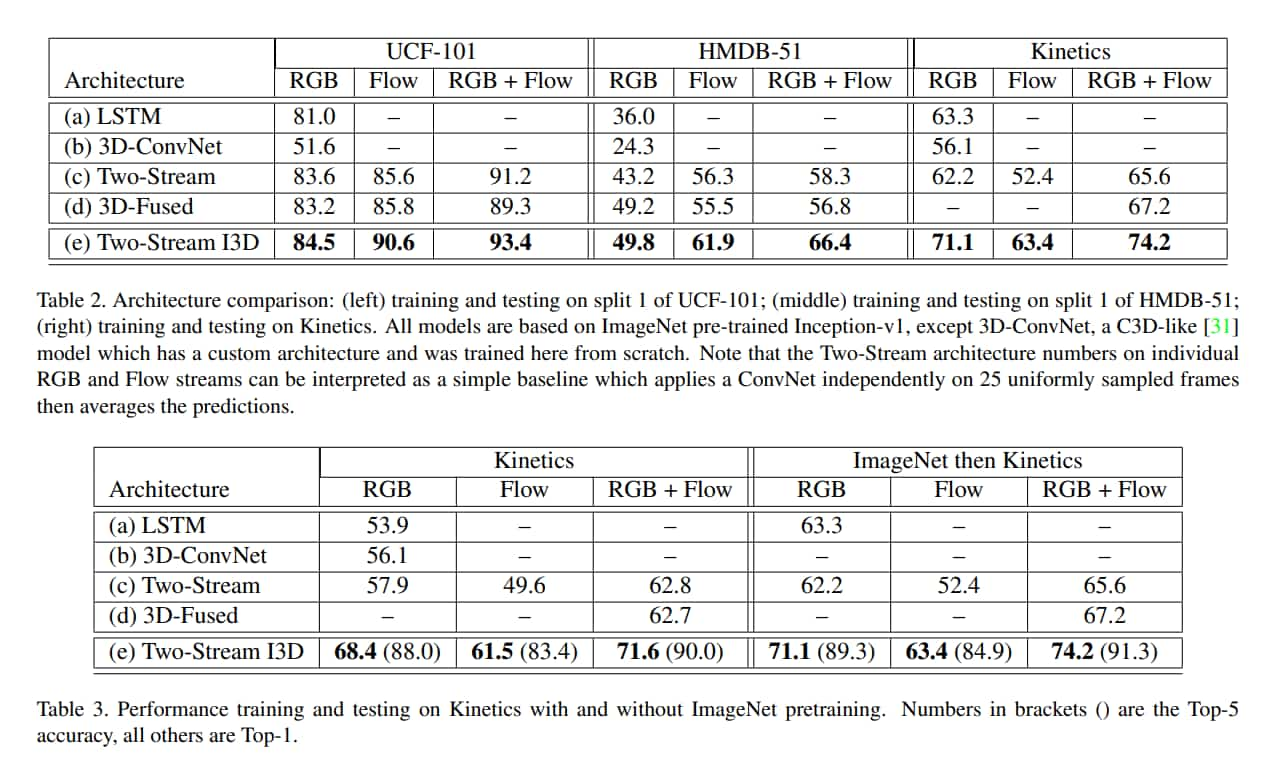
I3D 在所有資料集上都表現最好,甚至是在 UCF-101 和 HMDB-51 這種小資料集上也是如此,這意味著 ImageNet 預訓練的好處有成功擴展到 3D ConvNet。
多數模型在 UCF 上都表現得比 Kinetics 上好,顯現出資料集的難度差距。
但是在 HMDB 表現得較差,原因可能是 HMDB 故意弄得很難,作者有舉例,很多 clip 在完全相同的場景會有不同的動作。
作者有提到說 I3D 特徵比較好遷移的一種解釋是它具備 high temporal resolution, I3D 在 25 fps 的影片中用 64 frames 做訓練,使它能捕捉動作的 fine-grained 時間結構。
Experimental Evaluation of Features
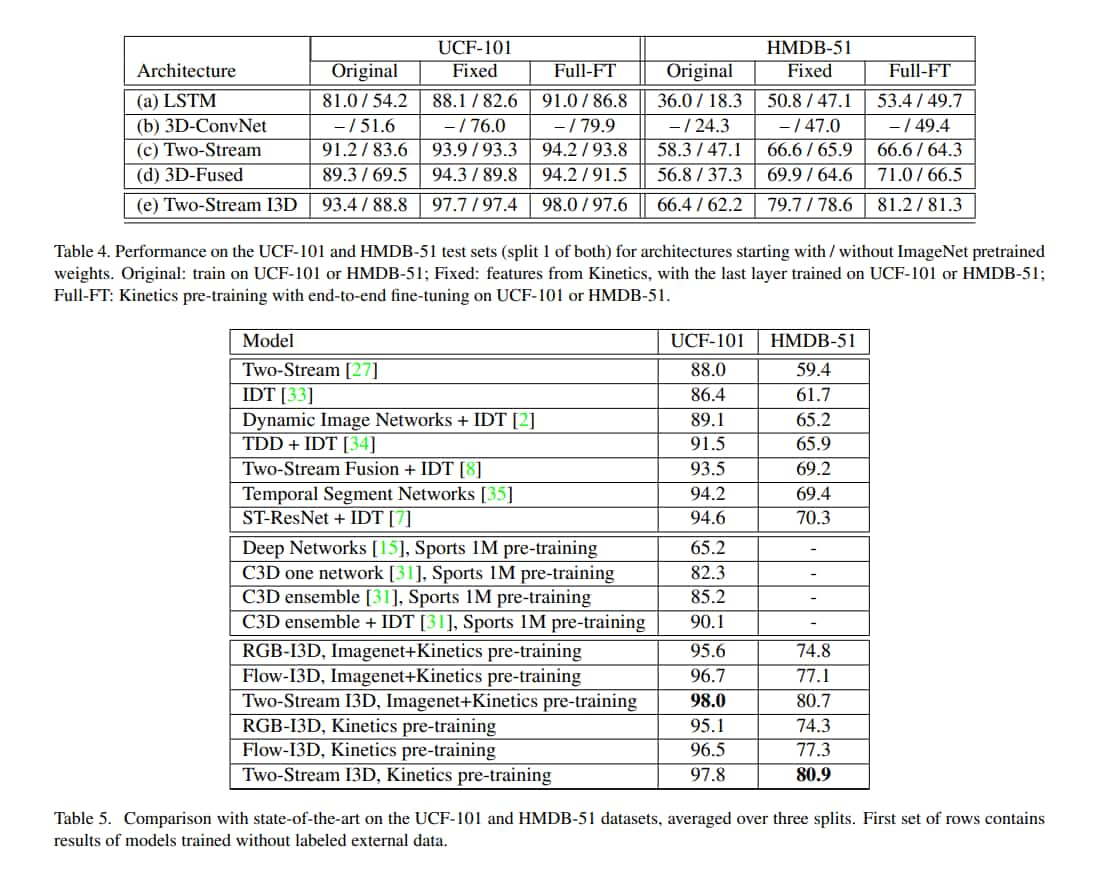
Kinetics 上做預訓練效果明顯比 ImageNet 好。
Discussion
Kinetics 上的預訓練對於遷移學習有明顯好處,但對於其他影像任務,比如影像語義分割是否有好處仍待觀察。
目前對於架構沒有全面探索,比如沒有採用 action tubes 或是 attention 機制。