paper: GIT: A Generative Image-to-text Transformer for Vision and Language
|
|
Abstract
設計了一個 Generative Image-to-text Transformer,統一 vision-language tasks,像是 image/video captioning 或是問答。
雖然 generative models 在預訓練和微調的時候是同樣的網路架構,現有的工作通常都包含複雜的架構 (uni/multi-modal encoder/decoder), 而且依賴於外部模組,比如物件偵測或 optical character recognition (OCR)。
在 GIT,我們簡化為 single language modeling task 下的一個 image encoder 和一個 text decoder。
擴大了預訓練資料和模型大小以提高模型性能。
在許多具有挑戰性的 benchmarks 上取得 SOTA。
比如首次在 TextCpas 上超越人類的表現。
提出了一種 generation-based image classification and scene text recognition 的新方案。
Introduction
近年來在 vision-language(VL)預訓練方面取得了巨大進展,特別是基於 image-text pairs 的大規模數據,例如 CLIP、Florence 和 SimVLM。
學習到的 representation 很好的提高了下游任務的性能,比如 image captioning、visual question answering 和 image-text retrieval。
在預訓練過程中,Masked Language Modeling (MLM) 和 Image-Text Matching (ITM) 被廣泛使用。
然而這些 loss 和下游任務不同,必須做 task-specific adaptation。
比如, image captioning 要移除 ITM,VQA 需要額外隨機初始的 MLP。
為了減少這種差異,最近的研究試圖為預訓練模型設計 unified generative models 來預訓練,因為大多數 VL 的問題可以轉化為生成問題。
這些方法通常利用 multi-modal encoder 和 text decoder,並精心設計 text input 和 text target。
為了進一步推動這方向的研究,作者設計了一個簡單的 Generative Image-to-text Transformer,稱作 GIT,只包含一個 image encoder 和 text decoder。
預訓練任務只是把輸入的圖像映射到相關聯的文字描述。
盡管他很簡單,但還是在眾多具有挑戰性的 benchmark 取得 SOTA。
image encoder 是 Swin-like vision transformer,在大量的 image-text pairs 上做 pretrain,基於 contrastive task。
這消除了現有許多方法中對 object detector 的依賴。
為了將其擴展到影片領域,我們把多個 frame 的特徵 concatenate,作為 video 表示。
text decoder 是一個用來預測相關聯文字的 transformer。
整個網路都是基於 language modeling task 來訓練。
對於 VQA,input question 被看作 text prefix,並以 auto-regressive 的方法生出答案。
此外,作者提出了一種 generation-based 的 ImageNet classification 新方案,預測標籤直接根據作者的生成模型,而不用預先定義詞彙表。
我們的作法很簡單,但在擴大預訓練資料和模型大小後,成果驚人。
主要貢獻如下:
-
我們展示了 GIT,僅由一個 image encoder 和一個 text decoder 組成,透過 language modeling task,在 0.8 billion image-text pairs 上 pretrain。
-
在 image/video captioning 和 QA 上,沒有基於 object detectors,object tags 和 OCR,就在多個任務上取得 SOTA。證明簡單的網路架構也可以透過 scaling 取得強大的性能。
-
我們證明 GIT 雖然 pretrain 在 image-text pairs,也能在 video tasks 上取得 SOTA,不需要 video dedicated encoders。
-
我們提出了一種新的 generation-based image classification 方案,在 ImageNet-1K 上,取得不錯的性能。
Related Work
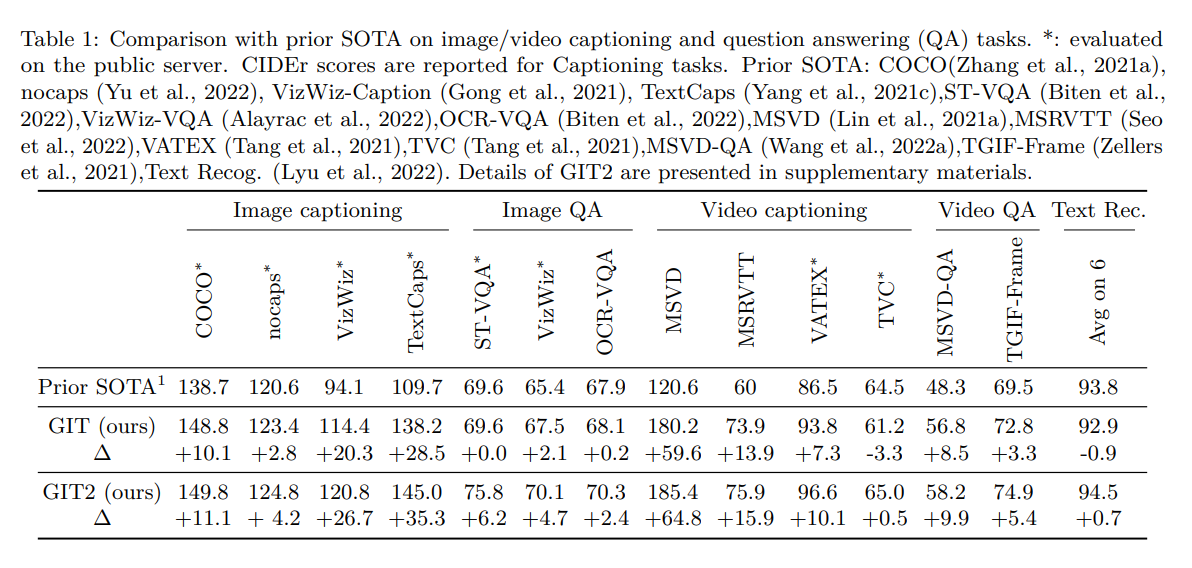

在 VL pre-training 中,多 multi-task pre-training 被廣泛使用,賦予網路多種或增強的能力。
比如,MLM 和 ITM 是廣泛採用的預訓練任務,最近也有研究加入 image-text contrastive loss。
由於多數 VL 任務都可以表示成 text generation task,所以可以訓練一個生成模型來支持各種下游任務。
輸入和輸出文本通常都會經過精心設計,以預訓練這樣的生成模型。
對於 image representation,Faster RCNN 被大多數現有方法用來提取區域特徵。
同時,也很容易以 end-to-end 的方法訓練整個網路。
除了 feature map,object tags,也很常被用來方便 transformer 理解上下文,特別是 novel objects。
對於與場景文本相關的任務,調用 OCR 以生成場景文本作為附加網路輸入。
對於 text prediction,常用 transformer network,結合 cross-attention module 來融合 image tokens。
或者只是單純 concatenate text tokens 和 image tokens,然後用 self-attention。
在本文中,我們有 9 個不同的 benchmark,3 種不同模型大小和 3 種不同預訓練資料規模。
Generative Image-to-text Transformer
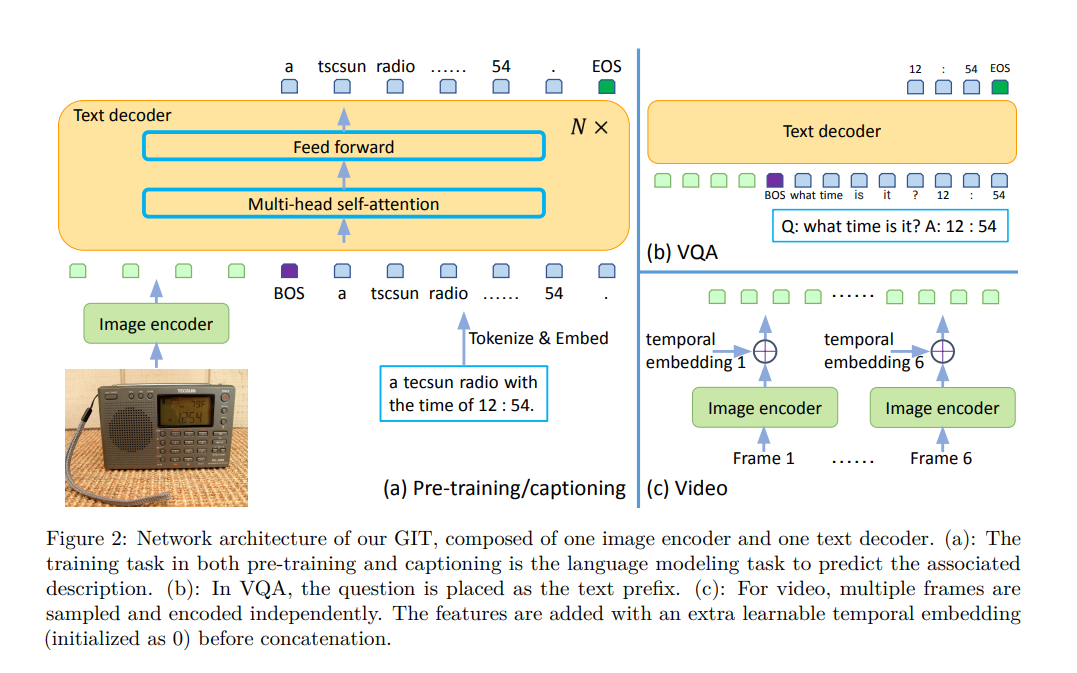
Network Architecture
image encoder 基於 contrastive pre-trained model。
輸入是原始圖像,輸出是 compact 2D feature map,被 flatten 成 list of features。
透過一個額外的 linear layer 和一個 layernorm layer,image features 被 project 到 D dimensions,也就是 text encoder 的 input。
作者使用做 contrastive tasks pretraining 的 image encoder,因為最近的研究表明這種 image encoder 有更好的性能。
在後面的章節,還觀察到 VL performence 明顯地隨著更強的 image encoder 而有所提升。 這和 object detection-based 的方法觀察到的結果一致。
CoCa 的 concurrent work 統一了 contrastive task 和 the generation task,作為一個預訓練階段。
作者的方法相當於是按順序分離兩個任務:
- 用 contrastive task 訓練 image encoder
- 用 generation task pretrain image encoder 和 text decoder
text decoder 是一個用於預測文本描述的 transformer module,由多個 transformer block 組成,每個 transformer block 由一個 self-attention layer 和 feed-forward layer 組成。
text 被 tokenize 和 embed 到 D dimensions,並添加 positional encoding 和 layernorm layer。
image features 和 text embeddings 被 concatenate 起來作為 transformer module 的輸入。
text 以 [BOS] 開始,並以 auto regressive 的方式 decode,直到 [EOS] 或 maximum steps。
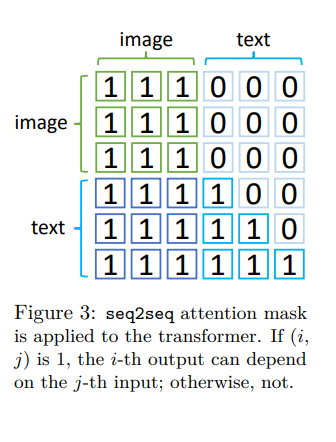
attention mask 根據上圖設計,使的 text token 只能依賴於前面的 text token 和 image token,而 image token 可以互相做 attention。
這和 unidirectional attention mask 不同,unidirectional attention mask 並非每個 image token 都可以依賴於其他的 Image token。
作者很好地初始化 image encoder,卻隨機初始化 text decoder。
這種設計動機是基於[MiniVLM: A Smaller and Faster Vision-Language Model],該研究隨機初始化顯示出與 BERT 初始化相似地性能。
原因可能在於 BERT 地初始化無法理解圖像信號,這對於 VL 任務至關重要。
[Flamingo: a Visual Language Model for Few-Shot Learning] 採用了類似的 image encoder + text decoder,但是他們的 decoder 經過 pretrain,並且有 freeze,好保留大型語言模型的泛化能力。
GIT 的所有參數都會更新,以更好地適應 VL 的任務。
另一種架構是 cross-attention-based 的 decoder,用於 incorporate image signals,而不是 concatenation 再用 self-attention。
根據實驗,large-scale 的 pre-training,self-attention-based 會有更好的性能,小規模的則是 cross-attention-based。
一個合理的解釋是,經過充分訓練,decoder 可以很好地處理圖像和文本,而且 image token 可以為了 text generation 更好地更新。
而 cross-attention 讓 image token 沒辦法 attend 彼此。
Pre-training
訓練採用 language modeling (LM) loss。
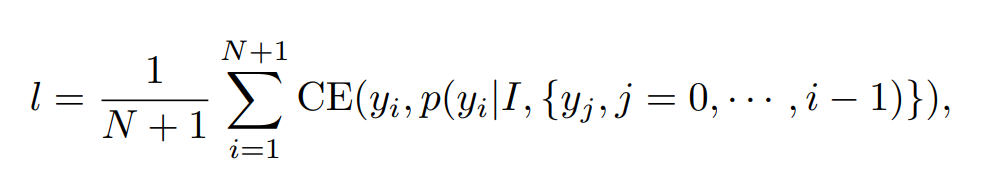
- $I$ 是 image
- $y_i,i \in $ { $ 1,…,N $ } 是文字 token,$y_0$ 是 [BOS],$y_{N+1}$ 是 [EOS]
- CE 是有 0.1 label smoothing 的 cross-entropy
另一種選擇是 MLM,在每個 epoch 中預測 15% 的輸入 token,要預測所有 token 至少需要 1 / 0.15 = 6.7 個 epochs,對於 LM,每個 epoch 都可以預測所有 token,對於大規模預訓練資料來說效率更高。
ablation studies 顯示出 LM 可以在有限的 epoch 內實現更好的性能。 在大規模訓練中,由於計算資訊的限制,只有兩個 epoch,所以選擇 LM。 與此同時,大部分最近的 large-scale language model 也是基於 LM。
如果沒有圖像輸入,該模型將簡化為 decoder-only 的語言模型,架構類似於 GPT-3。
因此,這種設計還可以利用 text-only 的資料來提升 scaled-up decoder 的能力,把這保留給未來的工作。
Fine-tuning
對於 image captioning,由於訓練數據格式和預訓練相同,所以用同樣的 LM task 來微調 GIT。 對於 visual question answering,問題和 GT 在微調的時候被看做 special caption,但 LM loss 僅用於答案和 [EOS]。
推理過程中,question 被當作 caption 的 prefix,完成的部分是預測。
VQAv2 現有的工作收集候選答案,再重構成分類問題,預測一次。 作者的工作有更多挑戰,因為是生成式的,需要生出至少兩個正確的 token,答案和 [EOS]。
然而考慮到自由形式答案的好處,作者選擇了生成方法。
由於生成模型的難度,VQAv2 比現有的判別工作略差。
對於和 scene-text related VQA 任務,現有方法通常利用 OCR 生成 5 個 scene text 並用 dynamic pointer network 決定當前輸出應該是 OCR 還是 general text。
但由於作者的方法不依賴於 OCR,因此也不依賴於 dynamic pointer network。
根據實驗,作者發現模型透過大規模預訓練資料學會如何閱讀場景文本,並且作者的模型不是專門為了影片領域設計的,但可以透過簡單的架構更改就取得具有競爭力或甚至 SOTA 的成果,也就是作者可以從每個影片採樣多個 frame,並透過 image encoder 獨立地為每個 frame 編碼。 最後添加一個 learnable temporal embedding (初始化為 0),並 concatenate sampled frames 的特徵。
作者還用於圖片分類,把 class name 用於 caption。
這和現有工作不一樣,現有工作通常先定義詞彙表,並用線性層預測每個類別的可能性。
當新數據和新類別被添加到現有數據的時候,這種新一代的方案是有益的,因為這樣可以在不引入新參數的情況下對新數據進行訓練。
Experiments
Setting
-
收集 0.8B 的 image-text pairs 來預訓練。
-
image encoder 是根據 pre-trained contrastive model 初始化的。
-
hidden dimension (D) = 768
-
text decoder 有 6 個 randomly-initialized transformer blocks
-
共有 0.7b 的參數
-
image decoder 和 text encoder 的 learning rate 各別是 1e-5 和 5e-5,都 cosine decay 到 0
-
推論階段 beam size 是 4,length penalty 是 0.6。
Supplementary materials 展示了小模型變體 (GITB and GITL) 和更大模型 (GIT2) 的結果
Results on Image Classification
輸出必須與類別名稱完全匹配,甚至考慮多或少的空格。
由於不知道詞彙表,精確匹被準確度只有 1.93%,如果預測包含 GT 就對,那有 40.88%。
通過微調每個類別只有 1 shot 或 5 shot,準確度會顯著提高, 表明只用少量訓練樣本,也可以輕鬆適應下游任務。
與 Flamingo 相比,GIT 實現更高的準確度。
Flamingo 在沒有參數更新的情況下進行小樣本學習,但需要額外的網路輸入,可能會增加推理成本。
相比之下,GIT 透過一次 lightweight fine-tuning,推理過程中不需要這些 training shot。
Analysis
Model and data scaling
對於網路架構,作者的模型被稱作 Huge,把 image encoder 換成 CLIP 的 ViT-B/16 和 ViT-L/14 的則是 Base 和 Large。
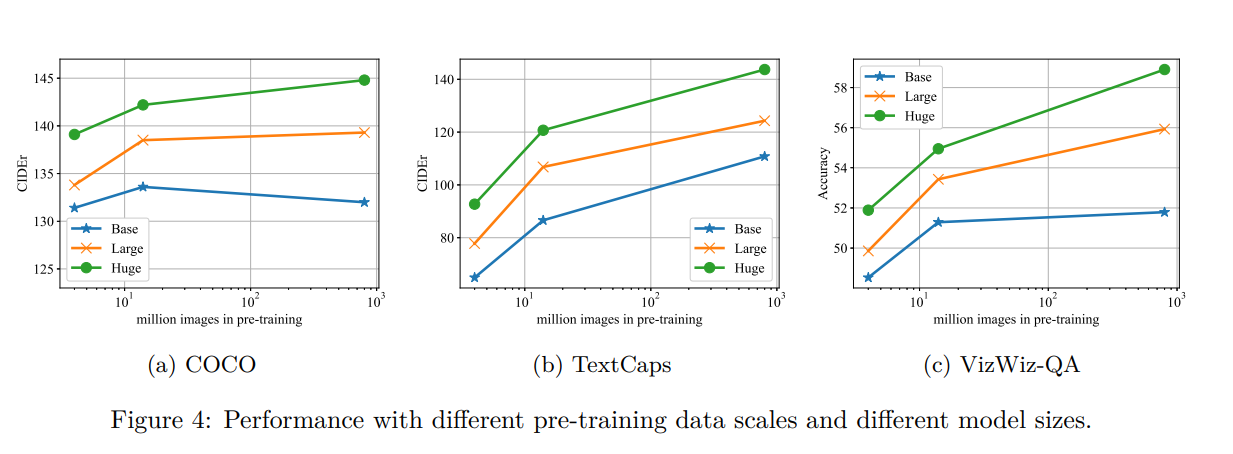
可以看出較大的 image encoder 帶來的好處,但根據實驗, 作者發現很難有效地擴展 text decoder,原因可能是 LM 很難用 limited amount of text 來訓練。
另一個可能的原因是 image encoder 負責 object recognition,而 decoder 負責以 NLP 的方法組織 object terms。 後一項任務可能很容易,因為大多數描述都遵循相似的模式,比如 Object + verb + subject,所以只要一個 small decoder,較大的 decoder 可能會增加學習難度。
Flamingo 的研究顯示更大的 Decoder 可以提高性能,但是他們的 decoder 有 pretrain 過,而且在 VL 預訓練的時候 frozen,避開了如何有效訓練 decoder 的問題。
LEMON 的 transformer 可以擴展到 32 層,可能是因為他們使用 MLM 而不是 LM,後者可能更加困難。
Scene text in pre-training data
為了瞭解 scene text comprehension 的能力,作者檢查了 pretrain data 有多少 image-text pairs 有 scene text。
作者用 Microsoft Azure OCR API4 對一些資料做 OCR,然後把 OCR 結果和 associated text 做比對,只有包含長度超過 5 個字元的 OCR 結果才會算比對。 有 15% 的 CC12M 和 31% 的下載圖像(500K) 包含 scene text 描述。 由於任務是訓練預測 text,網路逐漸學會閱讀 scene text。
Conclusion
Limitations
根據實驗,目前不清楚如何控制生成的 caption 以及如何在不更新參數的情況下執行 in-context learning,把這留給未來的工作。
Societal impact
該模型在大規模數據集上預訓練,不能保證數據不含 toxic language,可能會 poison output。
其他
A.3 Network
講超參數
