paper: Reading Wikipedia to Answer Open-Domain Questions
Abstract
本文提出以 Wikipedia 為知識來源來解決 open-domain question answering 問題
任何問題的答案都是 Wikipedia 中的一段文字
這項挑戰結合了文件檢索和理解文字的能力
本文的作法基於一個 search component,由 bigram hashing 和 TF-IDF matching 構成,並結合 RNN
對多個 QA 資料集做的實驗表明:
- 這兩個 components 對於現有的對應模塊具有高度競爭力
- 在他們的組合上使用 distant supervision 十分有效
Introduction
要把 wikipedia 當作知識來源,回答任何一個問題,都必須先從超過 5 百萬篇文章中找出少數相關的文章,並仔細掃描以找出答案。
本文將這稱為 machine reading at scale (MRS)
本文把 wikipedia 當作一個文章的集合,並且不依賴內部的 graph structure
因此該方法是通用的,可以套到諸如新聞、網路論壇等等的資料集上
本文開發了 DrQA,強大的維基百科問答系統,由以下部分組成:
- Document Retriever
- 一個用 bigram hashing 和 TF-IDF matching 的 module
- 用於在給定問題的情況下,返回有效相關文章的子集
- Document Reader
- RNN,用來 detect 文章中答案的位置
實驗表明 Document Retriever 的性能優於 Wikipedia 的內部搜尋引擎,Document Reader 在 SQuAD 上達到 SOTA
此外,與 single task training 相比,作者表明 multitask learning 和 distant supervision 有助於提高模型的性能
Related Work
隨著 Knowledge Base (KB) 的發展,QA 出現了許多創新,但是 KB 具備固有限制(incompleteness, fixed schema),促使研究人員轉回從 raw text 中提取答案
有些工作嘗試利用 multitask learning 來組合多個 QA 資料集,目標是:
- 透過 task transfer 來實現跨資料集的改進
- 提供一個單一通用的系統,可以回答不同種類的問題,因為資料來源中不可避免地存在不同的資料分布
本文的工作在先 retrive 再 read 的 setting 下,沒有利用 KB,取得了正面成果
DrQA
由兩個 Components 組成:
- Document Retriever
- 用來尋找相關文章
- Document Reader
- 用於從單一文件或一小部分文件提取答案
Document Retriever
遵循經典的 QA System,先用高效的 (非機器學習)的 document retrieval system 縮小搜索範圍,並專注於比較可能有關的文章
與基於 ElasticSearch 的 Wikipedia Search API 相比,簡單的 inverted index lookup 和 term vector model scoring 表現的十分好
文章和問題被表示為 TF-IDF weighted bag-of-words vectors
作者考慮透過考慮 local word order 和 n-gram features 來進一步改善
表現最佳的系統用 bigram counts,並利用 hashing 映射到 $2^{24}$ bins 來保持 speed 和 memory efficiency,用的是 unsigned murmur3 hash
Document Retriever 作為模型的第一部分,設定為對任何問題返回 5 個相關的文章
這些文章再交由 Document Reader 來處理
Document Reader
Paragraph encoding
$p_i$ 是段落 $p$ 中的 token,期望 $p_i$ 可以被 encode 成帶有周圍資訊的向量
採用的是 multi-layer bidirectional LSTM
特徵向量 $p_i$ 由以下部分組成:
-
Word embedding
- 用 300 維的 Glove word embedding,固定大部分預訓練的 word embedding,只 finetune 最常見的 1000 個 question words,例如 what, how, which
-
Exact match
- 採用三個簡單的 binary features,用來表示 $p_i$ 是否與問題中的 question word $q$ 精確匹配,無論是原始形式、小寫,還是 lemma form
-
Token features
- 作者添加了一些 manual feature 好反應 $p_i$ 在 context 中的屬性,比如 part-of-speech (POS)、named entity recognition (NER) tags 和它的 (normalized) term frequency (TF)
-
Aligned question embedding
- $f_{align}(p_i)=\sum_j a_{i,j}E(q_j)$
- $E$ 是 word embedding
- $a_{i,j}$ 是 attention score,計算 $p_i$ 和每個 $q_j$ 之間的 similarity
- $f_{align}(p_i)=\sum_j a_{i,j}E(q_j)$
Question encoding
這個比較簡單,只是在 word embedding 上加上一層 RNN,並把 hidden units 重新結合成一個向量
Prediction
把 $\{p_1,…,p_m\}$ 和 $q$ 作為 input,並個別單獨訓練兩個分類器預測開頭和結尾的位置
具體來說,作者用 bilinear term 來計算每個 $p_i$ 和 $q$ 之間的相似度,並計算每個 $p_i$ 是開頭的機率和結尾的機率
最後選擇最佳範圍,從 token $i$ 到 token $i'$
$i \le i’ \le i+15$
並且使 $P_{start}(i) \times P_{end}(i’)$ 最大化
Data
本文的工作依賴三種資料:
- Wikipedia
- 尋找答案的來源
- SQuAD
- 用來訓練和評估模型
- 另外三個 QA 資料集 (WebQuestions, CuratedTREC, WikiMovies)
- 用來測試模型在 Open-domain QA 上的泛化能力,並評估模型從 multitask learning 和 distant supervision 中獲益的程度
Wikipedia (Knowledge Source)
用 2016-12-21 dump2 的 English Wikipedia
對於每頁,只提取文本,並刪除結構化的資料(lists and figures)
丟棄 disambiguation pages, list, index 和 outline pages,保留了 5,075,182 篇文章
SQuAD
使用兩個 evaluation metrics:
- Exact string match (EM)
- F1 score
為了評估 open-domain QA 的能力,作者只有使用 SQuAD 的 QA pairs,要求系統在無法存取相關段落的情況下發現正確的 answer span
不像標準的 SQuAD setting 會給出相關段落
Open-domain QA Evaluation Resources
SQuAD 是目前可用的最大的 general purpose QA 資料集之一
收集過程包括向每個 human annotator 展示一個段落,並寫一個問題
因此,distribution 非常特定
作者建議在其他 open-domain QA 資料集上評估系統,他們以不同的方式建構
CuratedTREC
使用大版本,包含 TREC 1999, 2000, 2001 和 2002 的 2180 個問題
WebQuestions
這資料集旨在回答 Freebase KB 的問題
透過 Google Suggest API 抓問題,再用 Amazon Mechanical Turk 來獲取答案
作者用 entity names 把每個 answer 轉成答案,以便不引入 Freebase IDs
WikiMovies
包含對電影領域的 96k 個問答對
Distantly Supervised Data
上面說的資料集除了 SQuAD 都沒有相關段落,因此不能直接訓練 Document Reader
追隨之前已有的利用 distant supervision (DS) 來做 relation extraction 的工作,作者用一個程式自動把段落和此類訓練範例做相關聯
對每個問答對使用以下過程來建立訓練集:
首先,對問題用 Document Retriever 找到前 5 個相關的段落
與已知答案沒有 exact match 的段落都被直接丟棄
短於 25 個字元或長於 1500 個字元的段落也被丟棄
如果在問題中找到 named entity,不包含該 named entity 的段落也被丟棄
對於每個 retrived page 的每個段落,使用 question 和 20 token window 間的 unigram 和 bigram overlap 來計算相似度,保留重疊度最高的前五個段落
將找到的每個 pair 加入到 DS 訓練集中
大約一半的 DS 範例來自 SQuAD 以外的頁面
Experiments
Finding Relevant Articles
先檢查 Retriever 在所有 QA 資料集上的性能
計算 ration 是根據特定的問題,考慮這些問題對應的文本在前 5 個相關文章中的比例
結果表明,比 Wikipedia Search 還更好,尤其是使用 bigram hashing 的情況下
Reader Evaluation on SQuAD
Implementation details
使用 h=128 的 3 層雙向 LSTM,來做 paragraph encoding 和 question encoding
使用 Stanford CoreNLP 來做 tokenization 並生成 lemma, part-of-speech 和 named entity tags
Optimizer 使用 Adamax
Dropout rate 為 0.3
Result and analysis
作者的系統可以在 SQuAD 上達到 SOTA
做了 ablation study,結果表明所有功能都會影響性能
有趣的是,單獨沒有 $f_{alignd}$ 或 $f_{exact_match}$ 對性能不會有極大的影響,但兩個都沒有就會急遽下降
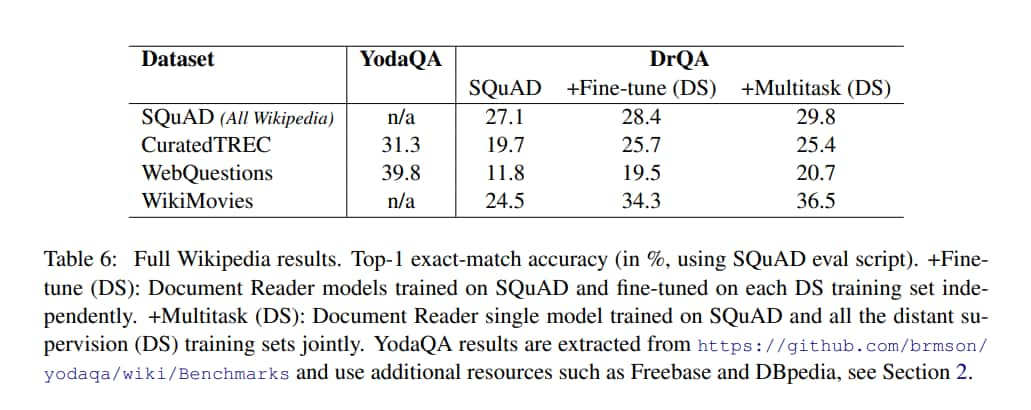
Full Wikipedia Question Answering
比較三個版本的 DrQA:
- SQuAD
- 只在 SQuAD 上訓練,並用於所有評估資料集
- Fine-tune (DS)
- 先在 SQuAD 上預訓練,在用 DS 訓練集對每個資料集進行微調
- Multitask (DS)
- 在 SQuAD 和 DS 訓練集上聯合訓練
Results
Conclusion
兩個明顯的 angles of attack:
- 把多個段落直接納入 Document Reader 的訓練,因為他目前獨立訓練每個段落
- 實作一個 end-to-end training 的 pipeline,可以在一個模型中結合 Document Retriever 和 Document Reader