paper: Dense Passage Retrieval for Open-Domain Question Answering
Abstract
Open-domain question answering 依賴有效的 passage retrieval 來選擇 candidate context,傳統上用的 sparse vector space models,有 TF-IDF、BM25 等等
本文顯示出檢索實際上可以只用 dense representation,embedding 是從少量的 question 和 passage 學到的,利用簡單的 dual-encoder framework
在廣泛的 open-domain QA 資料集上,本文的 dense retriever 在 top-20 passage retrieval accuracy 上比 Lucene BM25 好 9%-19%
並幫助作者的 end-to-end QA system 在 multiple open-domain QA benchmarks 上取得 SOTA
Introduction
早期閱讀理解模型提出了簡單的 two-stage framework:
-
一個 context retriever 先選定一些 passage 子集合,其中某一些 passage 包含答案
-
一個 machine reader,可以徹底檢查選出的 context 並找到答案
盡管將 open-domain QA 簡化為 machine reading 是一個合理的策略,但是實際上經常看到嚴重的性能下降,顯示出需要改進 retrieval
open-domain QA 中的 retrieval 通常用 TF-IDF 或 BM25 來實現,可以透過 inverted index 有效地 match keywords,而且把 question 和 context 表示為 high-dimensional sparse vectors
相反的,Dense latent semantic encoding 在設計上和 sparse representation 是互補的
例如,由完全不同的 token 組成的兩個同義詞依然可以映射到接近的向量
term-based system 相較 dense retrieval system 很難將比如「壞人」和「惡棍」匹配
Dense encoding 也可以透過調整 embedding function 來學習,對於 task-specific 的 representation 提供了彈性
透過特殊的 in-memory data structure 和 indexing scheme,可以用 maximum inner product search (MIPS) 來快速檢索
然而,人們普遍認為學習良好的 dense vector representation 需要大量的 QA labeled pair
因此,在 ORQA 之前,Dense retrieval 從沒被證明過可以在 open-domain QA 上贏過 TF-IDF 或 BM25
ORQA 提出了 ICT 來做額外的預訓練
盡管 ORQA 證明了 dense retrieval 可以超越 BM25,在多個 open-domain QA 資料集上取得 SOTA,但他也存在兩個弱點:
-
ICT 預訓練是 compute-intensive,而且不確定 regular sentence 是否能很好的替代 objective function 中的 question
-
由於 context encoder 沒有用 QA pair 進行 finetune,因此相應的 representation 可能不是最佳的
在本文中,本文將解決一個問題 – 我們是否可以只用 QA pair 來訓練更好的 dense embedding model,而不用額外的預訓練?
利用現在的 standard BERT pre-trained model 以及 dual-encoder architecture,本文專注於用相對少量的 question and passage pair 來訓練 dense retriever
經過一系列的 ablation study,本文的解決方案出奇的簡單
embedding 可以用最大化 question 和 相關的 passage 的 inner product 來訓練
作者的 Dense Passage Retrieval (DPR) 非常強大,不僅大幅優於 BM25,而且和 ORQA 相比,end-to-end QA 準確度也有大幅提升
作者的貢獻有兩部分:
-
作者證明在適當的設置下,只需在現有 question-passge pair 上 finetune question and passage encoder,就可以大幅超過 BM25,實驗結果也證明可能不用額外的預訓練
-
作者證明了在 open-domain QA 的背景下,更高的 retrieval accuracy 可以轉化為更高的 end-to-end QA accuracy
透過對 top retrived passage 使用 modern reader model,和幾個非常複雜的系統相比,作者在 open-retrieval setting 下的多個資料集取得了可比較或更好的結果
Background
本文研究的 open-domain QA 的描述如下:
先給出一個事實性問題,不屬於特定主題,需要一個系統使用大量多樣化主題的 corpus 來回答
更具體地說,作者假設 extractive QA setting,答案僅限於 corpus 中的一個或多個 passage 中出現的範圍
假設有 D 個 documents,先把每個 document 拆成多個等長的 text passage,好做為 basic retrieval unit,最後得到 M 個 passage in corpus C
每個 passage 可以被視作一個 token 序列
對於 question q,則是要找到某段 passage 中的一串連續的 token 來回答
值得注意的一點是,為了涵蓋盡可能廣泛的概念,corpus 的大小可能會從數百萬個文件到數十億個文件不等
因此,任何 open-domain QA system 都需要一個高效的 retriever,可以在 reader 提取答案前選擇一小組相關的文本
Dense Passage Retriever (DPR)
作者的研究重點是改進 open-domain QA 的 retrieval component
給定 M 個 passage,DPR 的目標是把所有 low-dimensional continuous space 的所有 passage 都給 index,使它可以有效地檢所和輸入問題相關的 top-k passage
M 有可能非常大,比如本文有 21M 個 passage,而 k 通常很小,可能只有 20~100 個
Overview
用 dense encoder $E_P(.)$ 和 $E_Q(.)$ 來分別 encode passage 和 question,在計算兩者的 inner product 來衡量相似度
盡管確實存在測量 question 和 passage 之間更具表現力的模型形式,比如帶有 cross-attention 的 multi-layer networks,但是 similarity function 需要可以分解,才可以預先計算 passage 的 embedding
大多數 decomposable similarity function 是 Euclidean distance (L2) 的變換
比如,consine 是 unit vector 的 inner product,而 Mahalanobis distance 等同於在 transformed space 的 L2 distance
由於 ablation study 表示其他相似含數的表現相當,因此選擇更簡單的內積函數,並透過學習更好的 encoder 來改善 dense passage retriever
Encoder
本文採用兩個獨立的 BERT,並把 [CLS] token 的 representation 當作 output
Inference
推理階段,將 passage encoder $E_P$ 應用在所有 passage,並用 FAISS offline index
FAISS 是一個非常高效的 open-source library,用在 similarity search 和 clustering of dense vectors,可以輕鬆應用在數十億個向量上
在推論接段,計算 q 的 embedding,然後用 FAISS 來找到 top-k passages
Training
每一個 training instance 都包含問題 q,還有一個正 (相關) passage,以及 n 個負 (不相關) passages
Positive and negative passages
對於檢索問題,正例通常明確可用,而反例則通常要從非常大的 pool 中選擇
正例可能會在 QA 資料集給出,或是可以從答案找到,其他的段落預設情況下都可視為不相關
在實踐中,如何選擇負例常被忽視,但對於學習 high-quality encoder 可能很關鍵
考慮三種負例:
- 隨機
- Corpus 中隨機選擇
- BM25
- BM25 返回的 passage 不含答案,但包含最多 question token
- Gold
- positive 和 question 配對
第 2 和 3 種是在說拿其他問題的正例當負例
In-batch negatives
有 B 訓練實體,每個問題有 B-1 個 negative passage,只有 i = j 時,$(q_i, p_j)$ 是正例,其他都是負例
in-batch negative 的技巧已被用在 full batch setting 和 mini-batch setting
已被證明是學習 dual-encoder 的有效策略,可以增加訓練範例的數量
Experimental Setup
Wikipedia Data Pre-processing
用 DrQA 提供的預處理程式碼從 Wikipedia dump 中提取文章中乾淨的文字部分
此步驟將刪除 semi-structured data,比如表格和 info-boxes
接著將每天文章分成多個不相交的文字區塊,每個文字區塊由 100 個單字組成,作為 basic retrieval unit,最後會有 21,015,324 個 passage
每個 passage 也帶有標題以及 [SEP]
Selection of positive passages
由於 TREC, WebQuestions 和 TriviaQA 中只有 question-answer pair,因此使用 BM25 把包含答案最多的 passage 當作正例
如果檢索到的前 100 篇文章中沒有答案,則該問題會被丟棄
Experiments: Passage Retrieval
Main Results
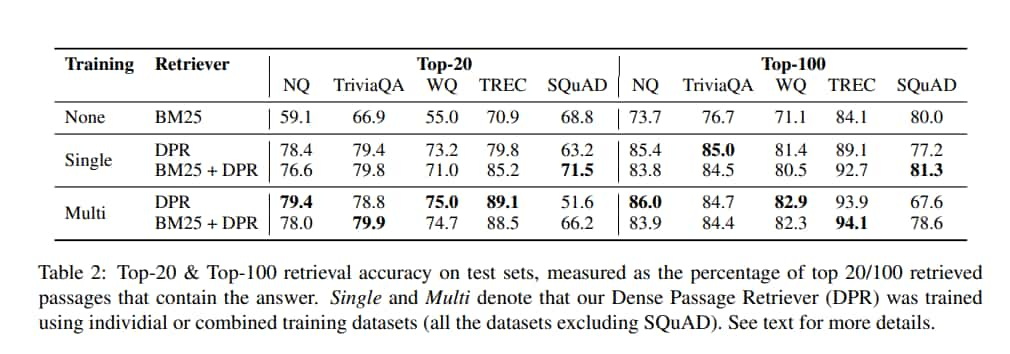
SQuAD 表現較差有可能是因為 passage 和 question 存在高度詞彙重疊,給 BM25 帶來優勢,而且資料僅從 500 多篇 wiki 文章中蒐集,因此訓練範例的分佈存在極大的 bias
當用多個資料集訓練時,TREC(裡面最小的資料集)獲益最多
Ablation Study on Model Training
Sample efficiency
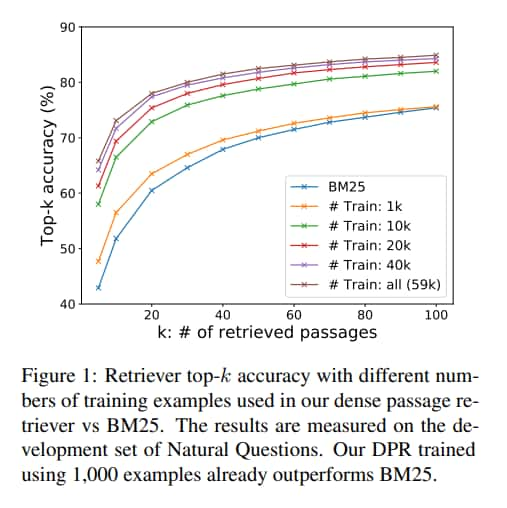
In-batch negative training
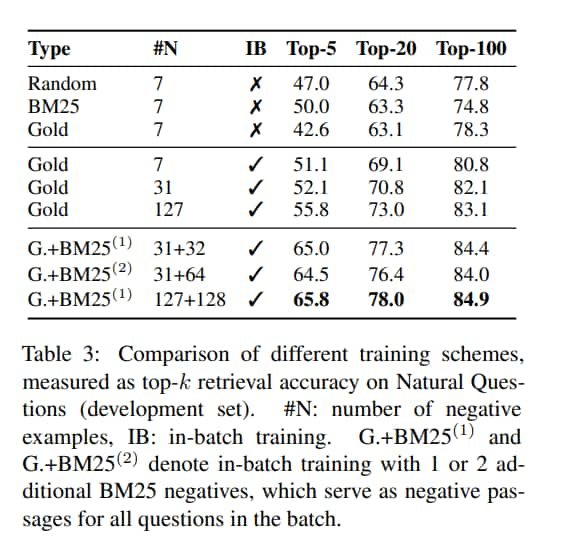
in-batch negative 可以顯著改善結果,還簡單且節省記憶體,可以重複使用 batch 中已經有的負例
它會產生更多 pair,從而增加訓練資料的數量
Impact of gold passages
做了 distant supervision,只有很小的影響,降低了 1 個點
Similarity and loss
L2 和 inner product 的表現相當,兩個都比 cosine 好
有一種流行的 ranking loss 叫做 triplet loss,但是在本文中,作者發現它的表現不會對結果產生太大影響
Cross-dataset generalization
為了測試泛化能力,只在 Natural Questions 上訓練,在較小的 WebQuestions 和 CuratedTREC 上測試,發現泛化能力很好,輸給 SOTA finetune model 3~5 個點,但仍大大優於 BM25 baseline
Experiments: Question Answering
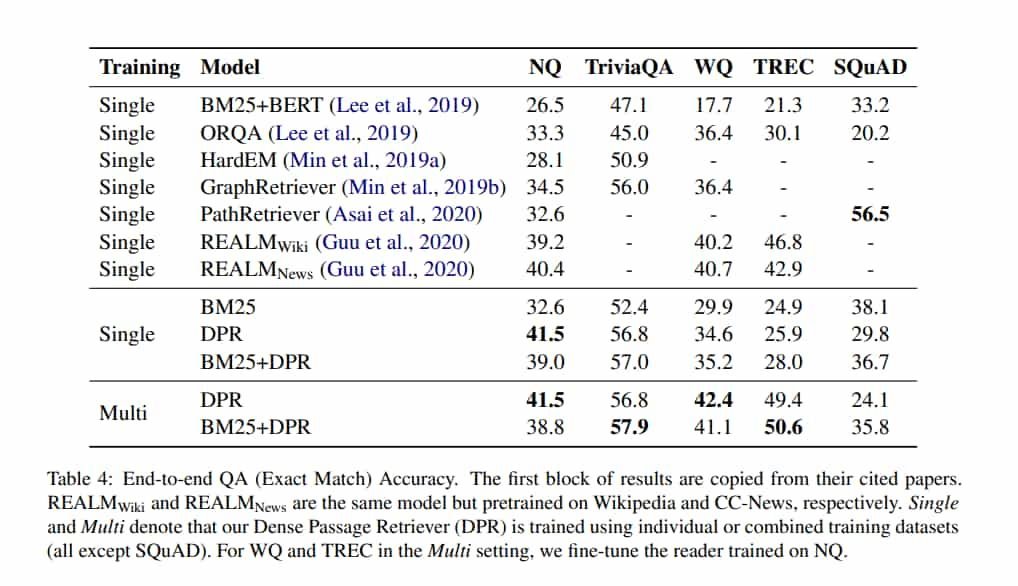
Result
Related Work
Conclusion
證明了 dense retrieval 可以 outperform 甚至可能取代傳統的 sparse retrieval
雖然簡單的 dual-encoder framework 可以達到很棒的效果,但作者顯示出要成功訓練也有一些關鍵因素
此外,根據 empirical analysis 和 ablation study,更複雜的 model framework 或 similarity function 不一定能提供額外價值
由於檢索性能的提高,在多個 open-domain QA benchmarks 上取得了 SOTA