paper: End-to-End Object Detection with Transformers
Abstract
作者把 object detection 視作一個 set prediction 問題。
簡化了 pipeline,消除了許多 hand-designed components,比如 non-maximum suppression 和 anchor generation,這些 component 由我們對於任務的先驗知識構成。
提出了一個新的目標函數,透過二分匹配(bipartite matching)進行預測,也用 Transformer encoder-decoder 架構。
給予一組固定的 learned object query,DETR 可以推理 objects 和 globol image context 的關係,並「並行」輸出一組預測集。
DETR 概念非常簡單。
DETR 在 COCO 上和 Faster RCNN baseline 在準確度和 performance 上相當。
DETR 可以很簡單地推廣到 Panoptic Segmentation。
Introduction
目標檢測的目標就是集合預測。
但目前都用一些很間接的方式去做,像是用 proposals, anchors 或 window centers。
但是這些方法性能明顯受限於後處理步驟,比如 non-maximum suppression,因為他們會產生大量冗餘的框。
為了簡化 pipeline,作者提出了一種 End-to-End 的方法,以往也有一些嘗試,但他們要不添加了其他的先驗知識,不然就是在具有挑戰性的 benchmark 上表現不好。
在 COCO 上和 Faster R-CNN 的性能相當,表現和速度都差不多。
DETR 在大物體表現很好,可能是歸功於 Transformer non-local 的計算能力。 雖然 DETR 在小物體上表現倒不怎麼樣。
DETR 需要超長的訓練時間,但 DETR 的設計理念可以拓展到 Panoptic Segmentation。
Related Work
Set Prediction
沒有規範的深度學習模型可以直接預測集合。
這些任務中的一個困難點是避免 near-dulicates(相近的重複檢測框) 當前多數檢測器用 NMS 來解決此問題,如果是 direct set prediction 就不用後處理。
Transformers and Parallel Decoding
Transformer 在各種地方表現出色,但推理成本令人望而生畏。
Object detection
現在多數的目標檢測方法是基於一些初始的猜測,再去做預測。
比如對於 two-stage 的方法,就是對於 proposals 往下做預測。
對於 single-stage,初始猜測就是 anchors。
Set-based loss
以前的一些作法比如 Learnable NMS 或 relation networks 都可以透過 attention 來處理不同預測之間的關係。
用 direct set losses,他們不需要任何後處理。
但是這些方法往往用額外的 hand-crafted context feature,比如 proposal box coordinates。作者尋找減少模型中先驗知識的方案。
Recurrent detectors
以往有類似的工作,但他們是用 RNN。
The DETR model
Object detection set prediction loss
DETE 會給 N 個固定大小的集合預測。
要解二分圖匹配,本文用 scipy 的 linear_sum_assignment 處理,他背後是匈牙利演算法。
其實這種方法和 proposals 和 anchors 有差不多的作用,差別在於這裡會找一對一的匹配,而不用重複。
目標函數:
$L_{Hungarian}(y, \text{\^{y}}) = \displaystyle\sum^{N}_{i=1} [-log \text{\^{p}} $ $_{\^{\sigma}(i)}(c_i) + \text{1}$ $_\{$ $_{c_i \neq \text{\o}}$ $_\}$ $\mathcal{L}$ $_{\text{box}} (b_i, \text{\^{b}}$ $_{\^{\sigma}}(i))]$
前面是分類的 loss,後面是 bounding box 的 loss。
這邊有兩個改動,第一個是分類那邊不用 log,使值和 bounding box 的 loss 比較接近。
另一個是 bounding box 那邊並不是用最常見的 L1,因為 L1 對於大的目標 loss 比較高,這裡除了 L1 還選用 generalized IoU loss,它在尺度上與 loss 無關。
DETR architecture
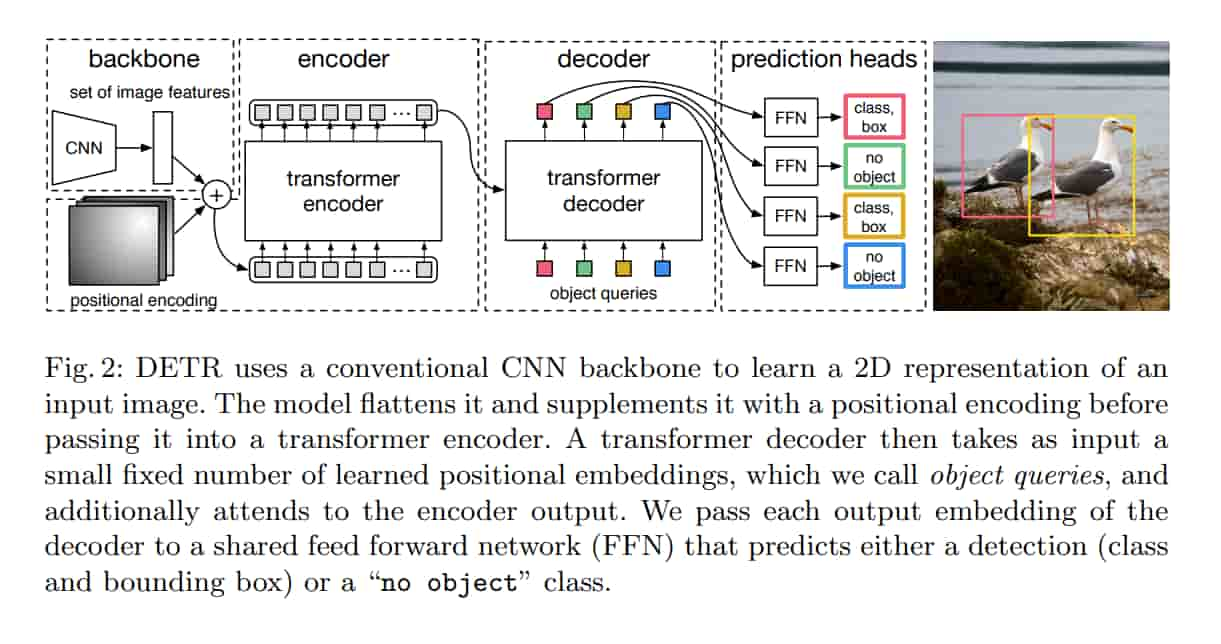
用 CNN 從圖片抽特徵,拉直,餵給 Transformer encoder-decoder,得到一組預測集合。
這裡 encoder 有助於特徵間彼此交互。
訓練的時候,預測的框和 GT 做匹配,沒匹配到的就放到 “no object” class。
decoder 會餵入 object queries,這些是 learnable positional encodings。
Experiments
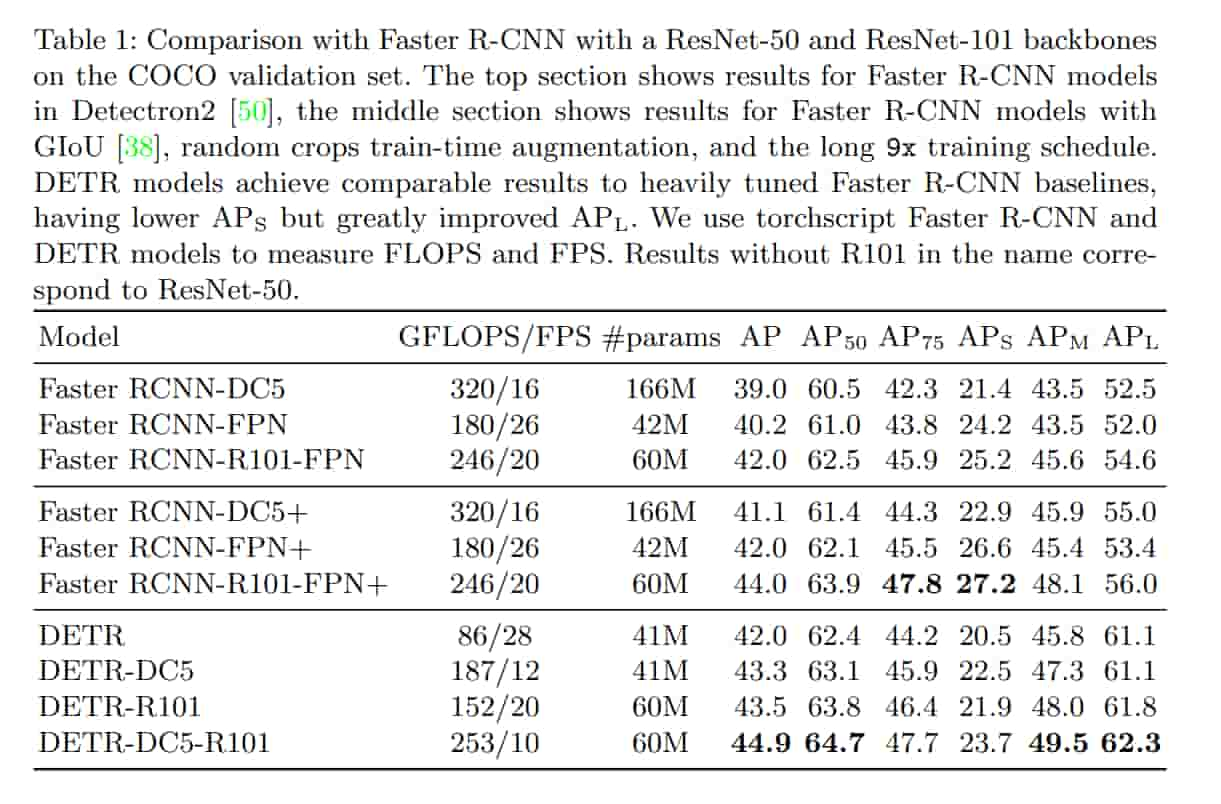
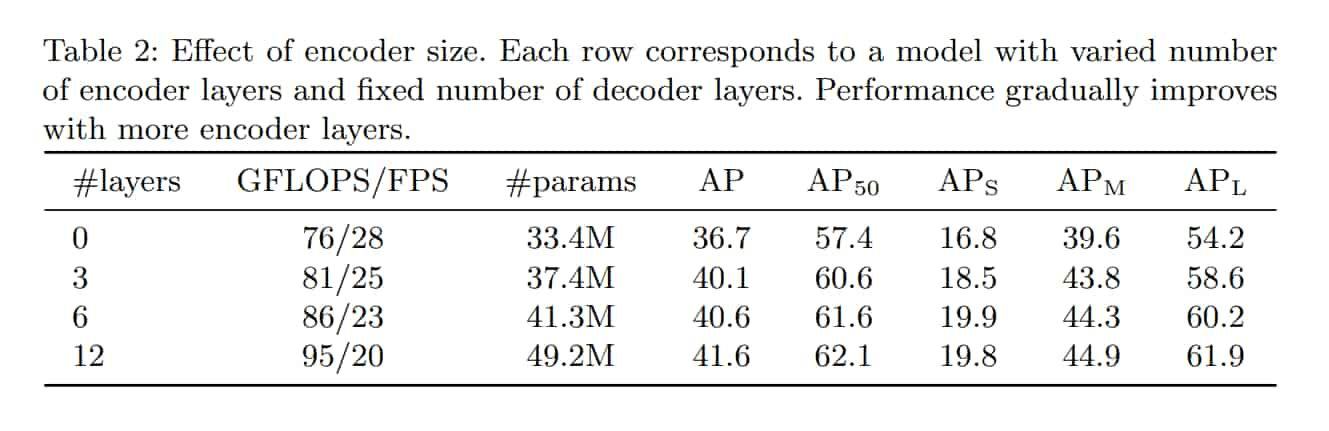
Ablations
Number of encoder layers

作者透過改變 Encoder layer 的數量來評估 global imagelevel self-attention 的重要性。
作者推論 encoder 可能對於判斷分開對象很重要,圖 3 可視化了最後一個 encoder layer 的 attention map。
encoder 看似已經分離了 instance,可能簡化了 decoder 對於 object extraction 和 localization 的工作。
Number of decoder layers

在圖 6 做了 decoder 的注意力可視化,可以注意到觀察的注意力相當局部。
推論是 encoder 主要分離實體,decoder 只需要關注四肢即可提取出對象的邊界和分類。
Analysis

圖 7 把 100 個預測槽中的 20 個做可視化。
每個預測框代表一點,可以注意到不同的槽位會專注在不同區域。