paper: Learning Transferable Visual Models From Natural Language Supervision
Abstract
現有的 SOTA CV system 可以經過訓練預測一組固定的類別。 但這種監督式的方法也受限了通用性,因為需要額外的 labeled data 來擴展。
直接從 raw text 學習 image 是個有前途的替代方案。
本文證明了「預測哪個是圖片的 caption」這種形式的預訓練是一種高效且可擴展的方法,可以從 internet 上蒐集的 4 億對資料從頭學習到 SOTA image representation。
預訓練後,透過自然語言來引導,就可以在下游任務十線 zero-shot。
本文對 30 個不同的現有電腦視覺資料集進行比較,可以在多數任務和監督式學習的 baseline 競爭,而且無須任資料集來做特別的訓練。
例如在 ImageNet 上做 zero-shot 可以和 ResNet-50 取得相近的準確度。
Introduction and Motivating Work
直接從原始文本學習的預訓練方法在過去幾年徹底改變了 NLP。
Task-agnostic (與下游任務無關) objectives,比如 autoregressive 和 masked language modeling,讓模型得以隨著 compute, model capacity, 和 data 規模的增長,使能力也逐步提升。
在 “text-to-text” 這種輸入輸出形式的預訓練,使模型轉移到下游任務的時候,不用特地客製化 output head,或對資料集做特別地處理。
這些結果表明,現代的預訓練方法在 web-scale 的文字集合的表現已經超過了用高品質的人為標記 NLP 資料集。
然而在 CV 等領域,在 ImageNet 這種人為標記的資料集上做預訓練卻依然是標準做法。
直接從網路文本學習的可擴展預訓練方法或許能在 CV 帶來類似的突破。
以往有一些工作嘗試利用幾乎無限量的原始文本而不是有限數量的 “gold-labels”, 但是這些方法都有一些妥協,比如都利用 softmax 來執行預測,使其沒辦法應付新類別,嚴重限制了 zero-shot 的能力。
作者提了幾個弱監督學習的例子,他們利用額外的資料結合預訓練,來幫忙改善監督式學習的結果。
也提了幾個和 CLIP 類似的工作 VirTex, ICMLM, ConVIRT,想利用 Transformer,從 Natural Language 中學習 image representation。
這些 weakly supervised model 和最近從 NLP 學習 image representation 的方法有一個重大差異,規模。
最近的一些研究,比如一些弱監督學習在數百萬到數十億張照片上訓練了多個 accelerator years。但是和 CLIP 相似的研究只在二十萬張圖片上訓練了幾天。
本文將規模拉高,以縮短規模上的差距。
作者在 internet 上蒐集了 4 億對圖片和文字的資料,做成新的資料集,並提出了 CLIP,ConVIRT 的簡化版本。
作者在 30 幾個資料集上測試,基本上能和監督式的模型競爭。
如果用 linear-probe,比公開可用的 SOTA ImageNet model 還更好。
Approach
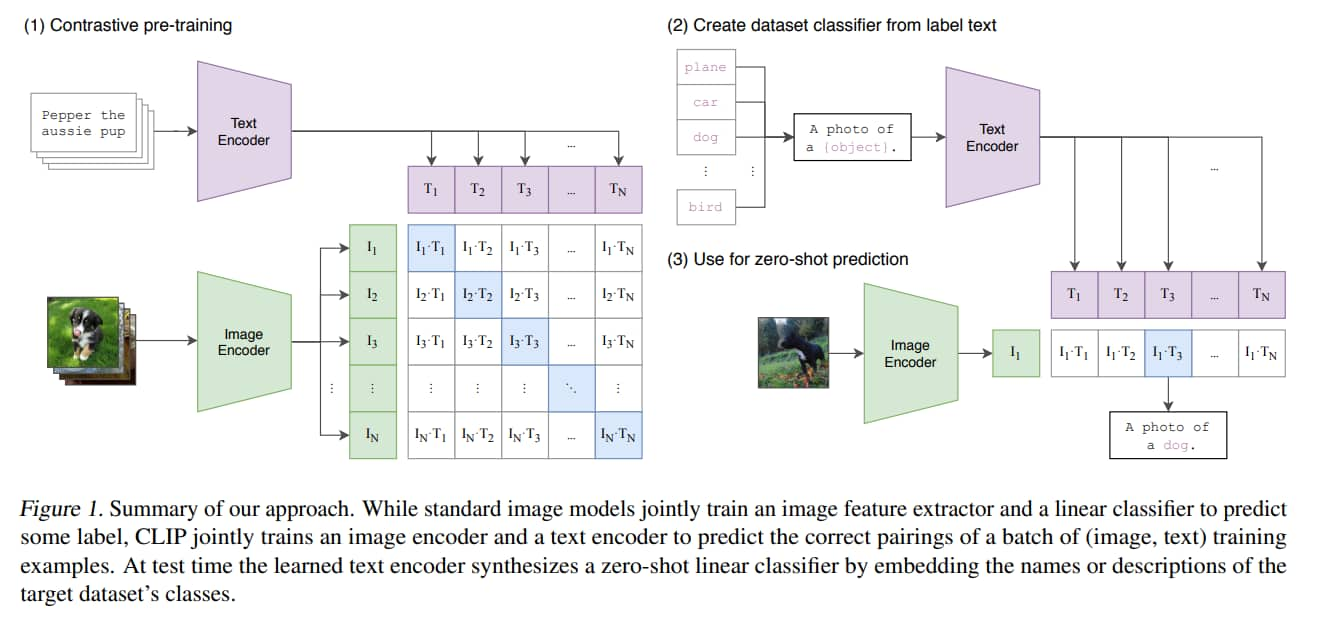
Natural Language Supervision
核心想法是利用 natural language 來學習 perception。
作者稱這不是一個新想法,但以往相似的方法的用語多樣,他介紹了四篇文章,但把從文字和圖片中學習 image representation 的方法個別稱為:無監督、自監督、弱監督、監督式。
擴展 natural language supervision 比起圖像分類簡單的多,不必定好類別,再去標註每張照片的類別。
而且 natural language supervision 還有個優勢,他不只能學習 image representation,還能將其和文字相關聯,使其更好做 zero-shot 的遷移。
Creating a Sufficiently Large Dataset
現有工作主要用三個資料集:
- MS-COCO
- Visual Genome
- YFCC100M
MS-COCO 和 Visual Genome 都是高品質的人為標記資料集,但是按照現代標準來看,它們很小,每個資料集大約有 100,000 張訓練照片。
相較之下,作者舉了一個最近的研究,用了 3.5 Billion 張 Instagram 照片作為訓練資料。
YFCC100M 是一個可能的替代方案,它有 100 million 張照片,但每張照片的 metadata 資料稀疏,而且良莠不齊。
比如許多檔名是自動產生的,可能是時間,或是相機的參數。
經過過濾,保留帶有自然語言的標題或描述的圖像,資料集縮小了 6 倍,只剩 15000 萬張照片,和 ImageNet 的大小相當。
natural language supervision 的一個主要動機是網路上公開著大量這種形式的 data。 由於現有資料集沒有反映這種可能性,因此只考慮這些資料集會低估這方面研究的潛力。
所以作者建立了一個新的包含 400 million pairs 的資料集,從網路上各種公開的來源蒐集的。
為了盡可能涵蓋所有的 visual concepts,作者在建構資料集的時候準備了 50 萬組特定的 query,每組 query 最多包含 20,000 個 pair,來進行 class balance。
產生的資料集的總字數和 GPT-2 用的 WebText 差不多。
將此資料集稱為 WIT,全名是 WebImageText。
Selecting an Efficient Pre-Training Method
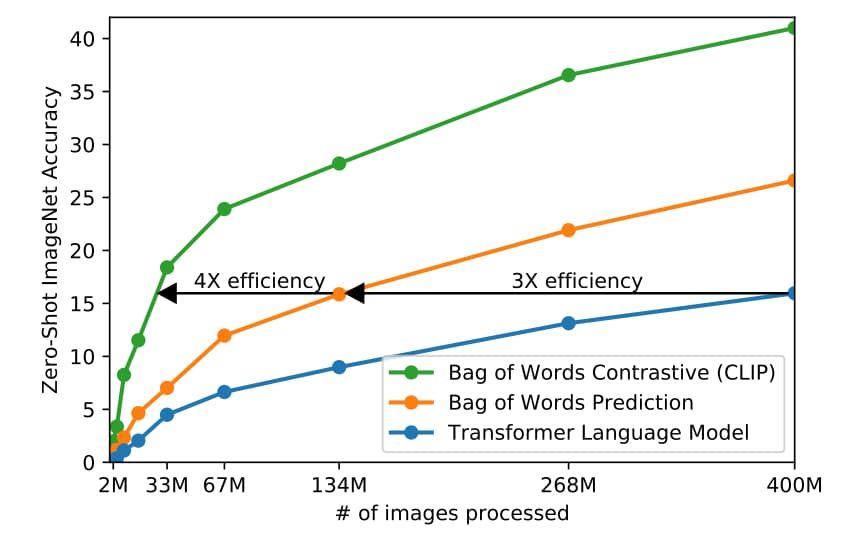
最先進的 CV System 需要大量的計算。
作者舉了兩個計算量都非常恐怖的模型,而且他們只能預測 1000 個 ImageNet 的類別。 其中一個花了 19 個 GPU years,另一個花了 33 個 TPUv3 core-years。 乍看之下,從自然語言中學習一組開放的視覺概念似乎令人生畏。
但在作者努力的過程中,他們發現訓練效率是成功擴展自然語言監督的關鍵,也根據該指標選定最終的預訓練方法。
最初的方法和 VirTex 相似,從頭開始訓練一個 CNN,和 text transformer 來預測 caption。
Fig.2 展示的 Transformer 語言模型的計算量是 ResNet-50 Image encoder 的兩倍。 預測 caption 比預測 caption 但採用詞袋的方式還慢三倍。
這樣預測 caption 是一個困難的任務,同一張照片對應的 caption 可能出現的描述甚至有非常多種。 最近在 Contrastive representation learning 方面的研究發現 contrastive objectives 有不錯的表現。
因此作者探索一種方法是,只預測文本和哪一個圖片配對,而不是預測確切的單字。
因為資料集超級大,overfitting 的問題影響不大。
此外,作者發現對於 encoder 的 representation,要轉換到 multi-model embedding space,只需要使用 linear projection 即可,不需要 non-linear,兩者之間差別不大。
Data augmentation 只有使用 random crop,而沒有使用其他的。
Choosing and Scaling a Model
|
|
Experiments
Prompt Engineering and Ensembling
一種常見的問題是 polysemy,一個單字可能有多種意思,比如 “boxer” 可能是一種狗,或是拳擊手。 如果一張圖片對應一個單字就會面臨這問題。
另一種是 distribution gap,比如訓練用句子,但測試用單字。 為了緩解這問題,作者發現用 prompt template “A photo of a {label}.” 比直接用 label 好。
光用這個 prompt template 就提高 1.3 % 在 ImageNet 上的準確度。
如果可以給其他額外訊息會更有幫助,比如對於寵物的資料集,可以用 “A photo of a {label}, a type of pet."。
對於 OCR 資料集,作者發現在要識別的文字或數字前後加上引號可以提高效能。
再來是 prompt ensembling,作者發現用多個 prompt template 來預測,然後綜合結果,可以提高效能。 作者用了 80 個 template。在 ImageNet 上比用單一的 prompt template 提高 3.5 % 的 performance。
綜合考慮 prompt engineering 和 prompt ensembling,作者在 ImageNet 上的準確度提高大概 5%。
- 這裡列幾個作者用的 prompt template:
- “a bad photo of a {}.”
- “a photo of many {}.”
- “a sculpture of a {}.”
- “a photo of the hard to see {}.”
Analysis of Zero-Shot CLIP Performance
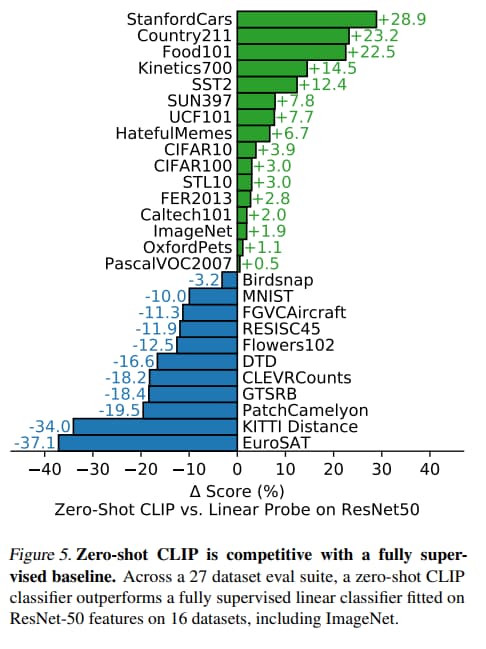
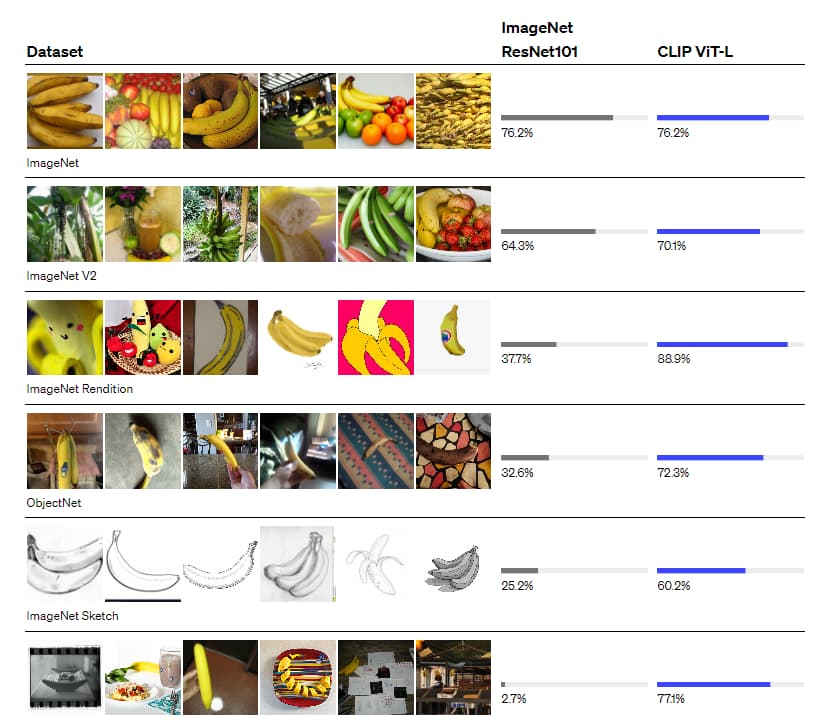
對於一般的物體分類的資料集,CLIP 表現較好。
下面有些複雜、專門、抽象的任務,CLIP 則表現的很差,比如計算場景中有多少物體的 (CLEVRCounts)、衛星圖像分類(EuroSAT)或是 識別最近的汽車距離(KITTI Distance)
對於這種特別難的任務,讓 CLIP 做 zero-shot 不太合理。 可能用 few-shot 的方式會比較好。
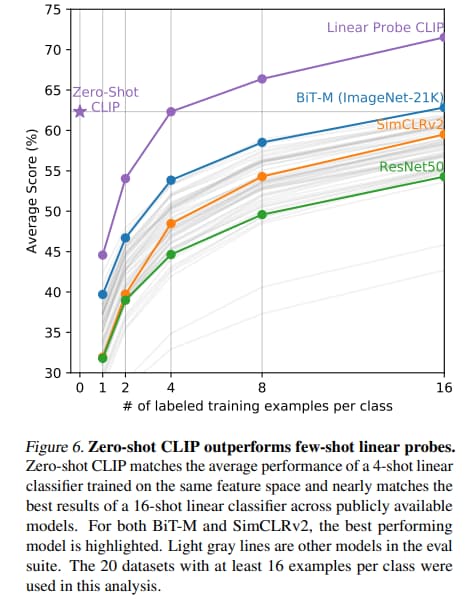
BiT 是 google 為 Transfer Learning 設計的預訓練模型,在分類問題,Few-shot learning 上有良好的表現。
Representation Learning
這節探討完全使用下游任務資料集而非 Zero-shot 或 few-shot 的情況。
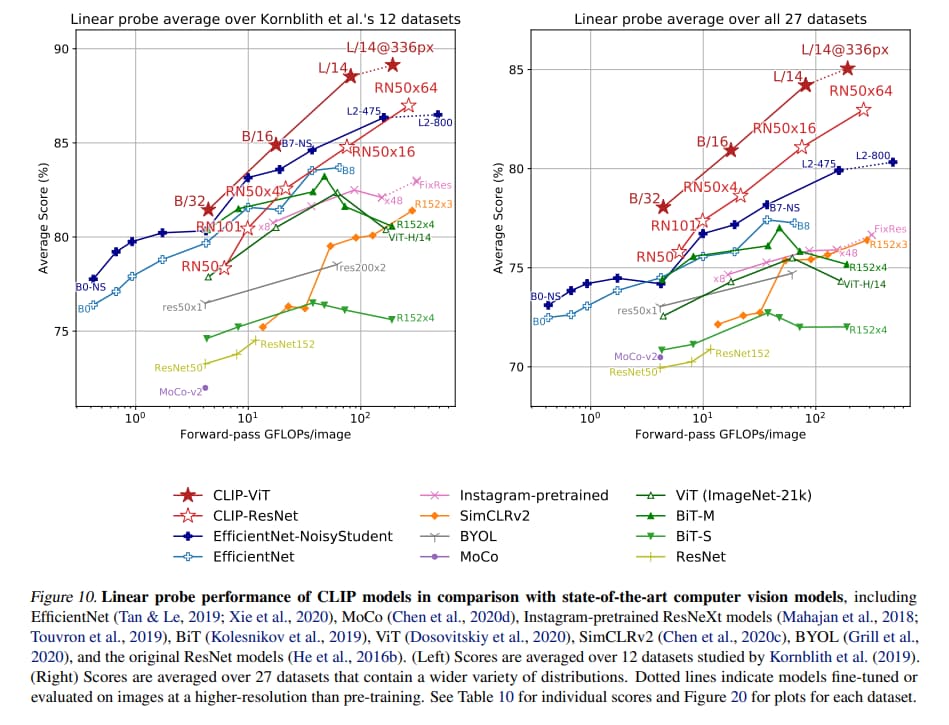
作者選用 linear-probe 而不是 finetune 來做下游任務的評估。
因為他們的重點是開發與資料集無關的預訓練方法,finetune 有可能讓一個預訓練學習 representation 失敗的模型在微調過程中變好。 而 linear-probe 的限制可以凸顯這些失敗。
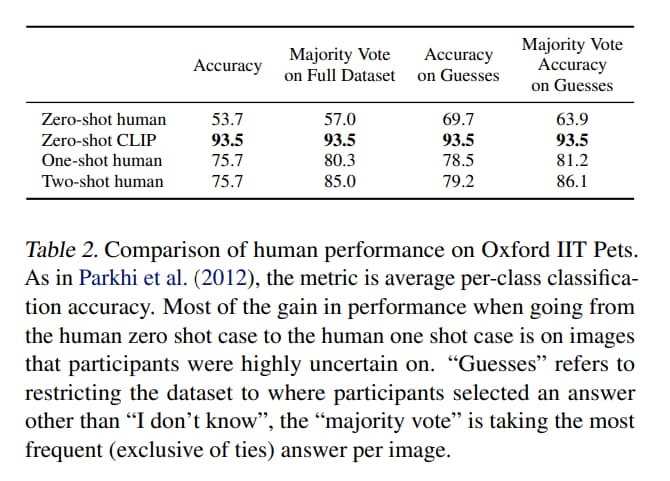
Comparison to Human Performance
再來是 CLIP 和人類相比的結果。 挑選了五個人在寵物資料集上比較的結果。
Data Overlap Analysis
可能會有人質疑,CLIP 的表現是因為訓練資料集和測試資料集有重疊。 但作者做了一些實驗,有些資料集完全沒有偵測到重疊。 對有重疊的做實驗,發現有重疊的對效果提升影響很小。
Limitations
CLIP 雖然可以和作為 Baseline 的 ResNet-50 打平手,但現在的 SOTA 遠高於該 Baseline。
作者發現再繼續加大模型和資料是可以繼續提升性能的,但作者估計要達到現有的 SOTA 需要增加大概 1000 倍的計算量才能達到,使用現有的硬體是不可行的。
CLIP 對細分類、抽象或更難的任務表現不好,作者相信還有許多任務是 CLIP 用 zero-shot 只能達到亂猜等級的。
Zero-Shot 的 CLIP 很難泛化到 out-of-distribution 的資料,比如在 MNIST 上只能達到 88% 的準確度。 作者發現預訓練資料幾乎沒有類似 MNIST 的圖片。
盡管 CLIP 可以靈活應用各種 Zero-Shot 的分類,但基本上還是從你給定的分類選擇。 和真正靈活的方法(生成 image caption)相比,是重大的限制。
一個值得嘗試的簡單想法是把 contrastive objective 和 generative objective,結合。
CLIP 也沒有解決深度學習資料效率低下的問題,CLIP 訓練了 32 個 epoch,如果把預訓練期間的照片以一秒一張來呈現,需要 405 年。 把 CLIP 和 self-supervision 或者和 self-training 做結合是有前途的方向。
雖然作者強調 Zero-Shot Learning,但是作者還是有反覆檢查下游任務測試集的表現,來調整 CLIP。 每次都用 ImageNet 來確認,並不算真正的 zero-shot 的情況。 如果能再創一個新的資料集,專門用來評估 zero-shot 遷移的能力會更恰當。
爬下來的資料有可能帶有社會偏見。
有一些複雜的任務很難用文字來傳達,雖然實際的訓練樣本有用,但 CLIP 並不會針對 few-shot 最佳化。有個違反直覺的結果,可以注意到在某些情況下,few-shot 不見得比 zero-shot 好。
額外應用
- 圖片生成
- StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery
- 用文字引導生成圖片
- CLIPDraw: Exploring Text-to-Drawing Synthesis through Language-Image Encoders
- StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery
- 物件偵測
- Open-Vocabulary Object Detection via Vision and Language Knowledge Distillation
- 將基礎類別再做細分類
- Open-Vocabulary Object Detection via Vision and Language Knowledge Distillation
- OCR
- Contrastive Language-Image Forensic Search
- 搜索影片中有沒有文本描述的物體
- Contrastive Language-Image Forensic Search
筆記
prompt engineering prompt ensemble